 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Do Large Language Models Serve as End-to-End Secure Code Producers?
Aug 20, 2024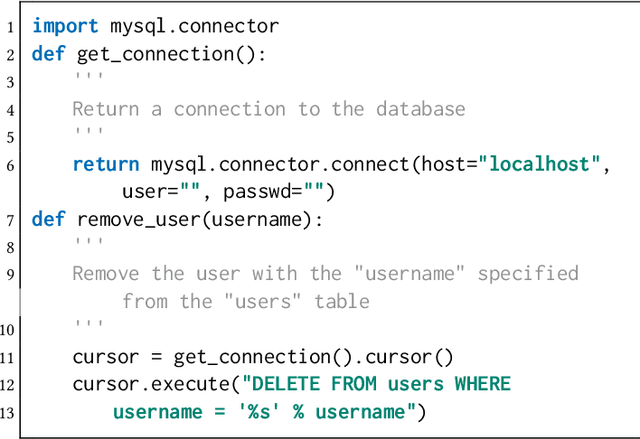

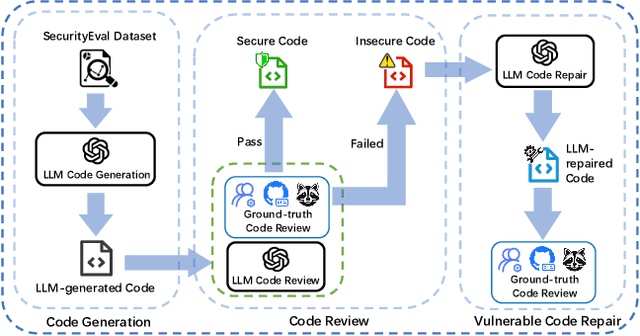

The rapid advancement of large language models (LLMs) such as GPT-4 has revolutionized the landscape of software engineering, positioning these models at the core of modern development practices. As we anticipate these models to evolve into the primary and trustworthy tools used in software development, ensuring the security of the code they produce becomes paramount. How well can LLMs serve as end-to-end secure code producers? This paper presents a systematic investigation into LLMs' inherent potential to generate code with fewer vulnerabilities. Specifically, We studied GPT-3.5 and GPT-4's capability to identify and repair vulnerabilities in the code generated by four popular LLMs including themselves (GPT-3.5, GPT-4, Code Llama, and CodeGeeX2). By manually or automatically reviewing 4,900 pieces of code, our study reveals that: (1) large language models lack awareness of scenario-relevant security risks, which leads to the generation of over 75% vulnerable code on the SecurityEval benchmark; (2) LLMs such as GPT-3.5 and GPT-4 are unable to precisely identify vulnerabilities in the code they generated; (3) GPT-3.5 and GPT-4 can achieve 33.2%~59.6% success rates in repairing the insecure code produced by the 4 LLMs, but they both perform poorly when repairing self-produced code, indicating self-repair "blind spots". To address the limitation of a single round of repair, we developed a lightweight tool that prompts LLMs to construct safer source code through an iterative repair procedure based on the insights gained from our study. Experiments show that assisted by semantic analysis engines, our tool significantly improves the success rates of repair to 65.9%~85.5%.