 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-CGL: An Efficient Continual Graph Learner
Aug 18, 2024Continual learning has emerged as a crucial paradigm for learning from sequential data while preserving previous knowledge. In the realm of continual graph learning, where graphs continuously evolve based on streaming graph data, continual graph learning presents unique challenges that require adaptive and efficient graph learning methods in addition to the problem of catastrophic forgetting. The first challenge arises from the interdependencies between different graph data, where previous graphs can influence new data distributions. The second challenge lies in the efficiency concern when dealing with large graphs. To addresses these two problems, we produce an Efficient Continual Graph Learner (E-CGL) in this paper. We tackle the interdependencies issue by demonstrating the effectiveness of replay strategies and introducing a combined sampling strategy that considers both node importance and diversity. To overcome the limitation of efficiency, E-CGL leverages a simple yet effective MLP model that shares weights with a GCN during training, achieving acceleration by circumventing the computationally expensive message passing process. Our method comprehensively surpasses nine baselines on four graph continual learning datasets under two settings, meanwhile E-CGL largely reduces the catastrophic forgetting problem down to an average of -1.1%. Additionally, E-CGL achieves an average of 15.83x training time acceleration and 4.89x inference time acceleration across the four datasets. These results indicate that E-CGL not only effectively manages the correlation between different graph data during continual training but also enhances the efficiency of continual learning on large graphs. The code is publicly available at https://github.com/aubreygjh/E-CGL.
SGL-PT: A Strong Graph Learner with Graph Prompt Tuning
Feb 24, 2023Recently, much exertion has been paid to design graph self-supervised methods to obtain generalized pre-trained models, and adapt pre-trained models onto downstream tasks through fine-tuning. However, there exists an inherent gap between pretext and downstream graph tasks, which insufficiently exerts the ability of pre-trained models and even leads to negative transfer. Meanwhile, prompt tuning has seen emerging success in natural language processing by aligning pre-training and fine-tuning with consistent training objectives. In this paper, we identify the challenges for graph prompt tuning: The first is the lack of a strong and universal pre-training task across sundry pre-training methods in graph domain. The second challenge lies in the difficulty of designing a consistent training objective for both pre-training and downstream tasks. To overcome above obstacles, we propose a novel framework named SGL-PT which follows the learning strategy ``Pre-train, Prompt, and Predict''. Specifically, we raise a strong and universal pre-training task coined as SGL that acquires the complementary merits of generative and contrastive self-supervised graph learning. And aiming for graph classification task, we unify pre-training and fine-tuning by designing a novel verbalizer-free prompting function, which reformulates the downstream task in a similar format as pretext task. Empirical results show that our method surpasses other baselines under unsupervised setting, and our prompt tuning method can greatly facilitate models on biological datasets over fine-tuning methods.
RoSA: A Robust Self-Aligned Framework for Node-Node Graph Contrastive Learning
Apr 29, 2022

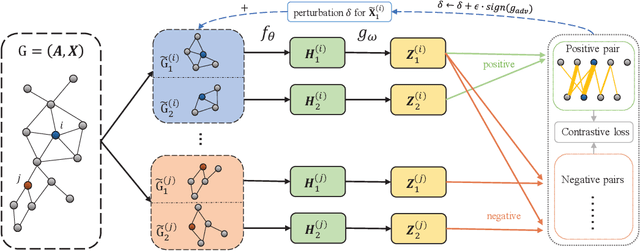

Graph contrastive learning has gained significant progress recently. However, existing works have rarely explored non-aligned node-node contrasting. In this paper, we propose a novel graph contrastive learning method named RoSA that focuses on utilizing non-aligned augmented views for node-level representation learning. First, we leverage the earth mover's distance to model the minimum effort to transform the distribution of one view to the other as our contrastive objective, which does not require alignment between views. Then we introduce adversarial training as an auxiliary method to increase sampling diversity and enhance the robustness of our model. Experimental results show that RoSA outperforms a series of graph contrastive learning frameworks on homophilous, non-homophilous and dynamic graphs, which validates the effectiveness of our work. To the best of our awareness, RoSA is the first work focuses on the non-aligned node-node graph contrastive learning problem. Our codes are available at: \href{https://github.com/ZhuYun97/RoSA}{\texttt{https://github.com/ZhuYun97/RoSA}}