 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Off-policy with Model-based Intrinsic Motivation For Active Online Exploration
Mar 31, 2024

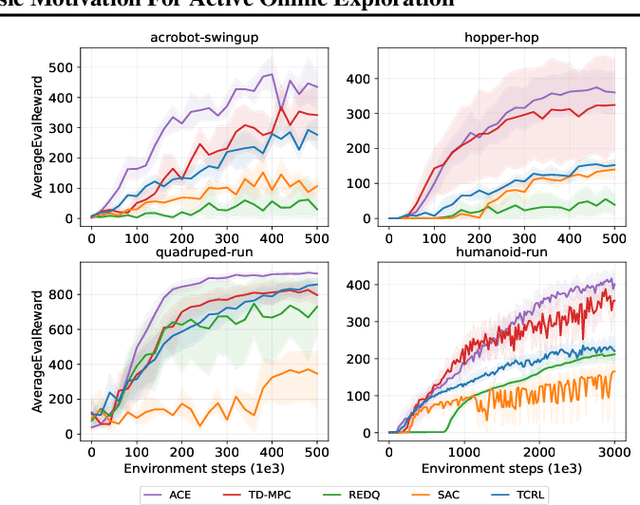

Recent advancements in deep reinforcement learning (RL) have demonstrated notable progress in sample efficiency, spanning both model-based and model-free paradigms. Despite the identification and mitigation of specific bottlenecks in prior works, the agent's exploration ability remains under-emphasized in the realm of sample-efficient RL. This paper investigates how to achieve sample-efficient exploration in continuous control tasks. We introduce an RL algorithm that incorporates a predictive model and off-policy learning elements, where an online planner enhanced by a novelty-aware terminal value function is employed for sample collection. Leveraging the forward predictive error within a latent state space, we derive an intrinsic reward without incurring parameters overhead. This reward establishes a solid connection to model uncertainty, allowing the agent to effectively overcome the asymptotic performance gap. Through extensive experiments, our method shows competitive or even superior performance compared to prior works, especially the sparse reward cases.