 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEq.Bot: Enhance Robotic Manipulation Learning via Group Equivariant Canonicalization
Nov 19, 2025Robotic manipulation systems are increasingly deployed across diverse domains. Yet existing multi-modal learning frameworks lack inherent guarantees of geometric consistency, struggling to handle spatial transformations such as rotations and translations. While recent works attempt to introduce equivariance through bespoke architectural modifications, these methods suffer from high implementation complexity, computational cost, and poor portability. Inspired by human cognitive processes in spatial reasoning, we propose Eq.Bot, a universal canonicalization framework grounded in SE(2) group equivariant theory for robotic manipulation learning. Our framework transforms observations into a canonical space, applies an existing policy, and maps the resulting actions back to the original space. As a model-agnostic solution, Eq.Bot aims to endow models with spatial equivariance without requiring architectural modifications. Extensive experiments demonstrate the superiority of Eq.Bot under both CNN-based (e.g., CLIPort) and Transformer-based (e.g., OpenVLA-OFT) architectures over existing methods on various robotic manipulation tasks, where the most significant improvement can reach 50.0%.
Physics-informed neural networks for hidden boundary detection and flow field reconstruction
Mar 31, 2025



Simultaneously detecting hidden solid boundaries and reconstructing flow fields from sparse observations poses a significant inverse challenge in fluid mechanics. This study presents a physics-informed neural network (PINN) framework designed to infer the presence, shape, and motion of static or moving solid boundaries within a flow field. By integrating a body fraction parameter into the governing equations, the model enforces no-slip/no-penetration boundary conditions in solid regions while preserving conservation laws of fluid dynamics. Using partial flow field data, the method simultaneously reconstructs the unknown flow field and infers the body fraction distribution, thereby revealing solid boundaries. The framework is validated across diverse scenarios, including incompressible Navier-Stokes and compressible Euler flows, such as steady flow past a fixed cylinder, an inline oscillating cylinder, and subsonic flow over an airfoil. The results demonstrate accurate detection of hidden boundaries, reconstruction of missing flow data, and estimation of trajectories and velocities of a moving body. Further analysis examines the effects of data sparsity, velocity-only measurements, and noise on inference accuracy. The proposed method exhibits robustness and versatility, highlighting its potential for applications when only limited experimental or numerical data are available.
MLOD: A multi-view 3D object detection based on robust feature fusion method
Sep 09, 2019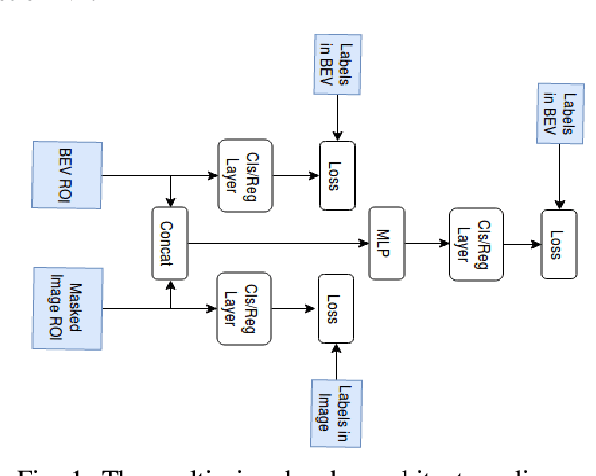


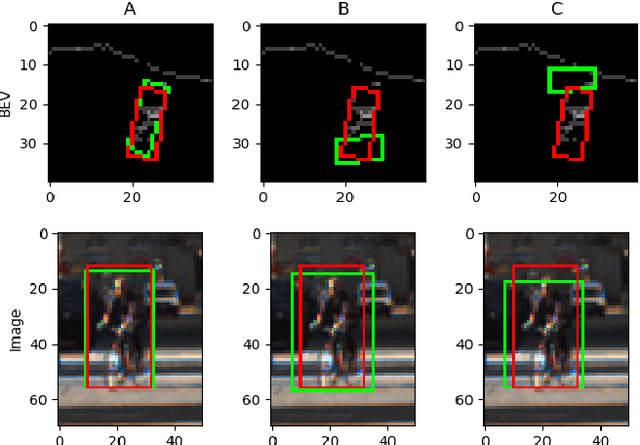
This paper presents Multi-view Labelling Object Detector (MLOD). The detector takes an RGB image and a LIDAR point cloud as input and follows the two-stage object detection framework. A Region Proposal Network (RPN) generates 3D proposals in a Bird's Eye View (BEV) projection of the point cloud. The second stage projects the 3D proposal bounding boxes to the image and BEV feature maps and sends the corresponding map crops to a detection header for classification and bounding-box regression. Unlike other multi-view based methods, the cropped image features are not directly fed to the detection header, but masked by the depth information to filter out parts outside 3D bounding boxes. The fusion of image and BEV features is challenging, as they are derived from different perspectives. We introduce a novel detection header, which provides detection results not just from fusion layer, but also from each sensor channel. Hence the object detector can be trained on data labelled in different views to avoid the degeneration of feature extractors. MLOD achieves state-of-the-art performance on the KITTI 3D object detection benchmark. Most importantly, the evaluation shows that the new header architecture is effective in preventing image feature extractor degeneration.