 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Probability of Agreement
Aug 12, 2022
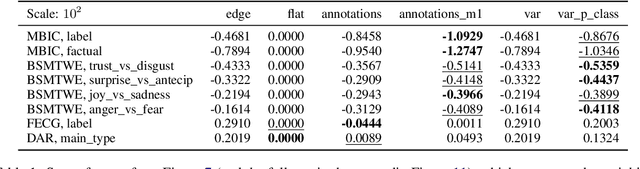
Measuring inter-annotator agreement is important for annotation tasks, but many metrics require a fully-annotated dataset (or subset), where all annotators annotate all samples. We define Sparse Probability of Agreement, SPA, which estimates the probability of agreement when no all annotator-item-pairs are available. We show that SPA, with some assumptions, is an unbiased estimator and provide multiple different weighing schemes for handling samples with different numbers of annotation, evaluated over a range of datasets.
Probabilistic Decoupling of Labels in Classification
Jun 16, 2020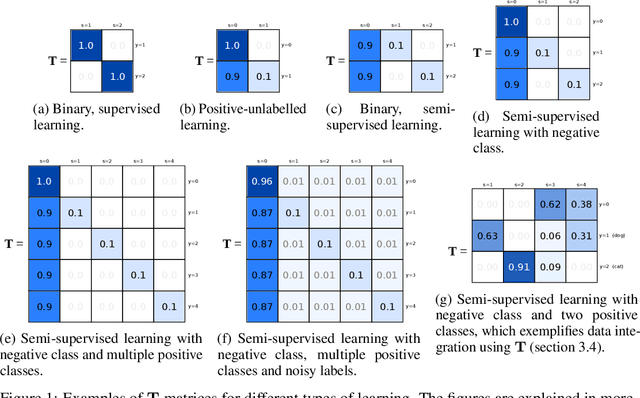
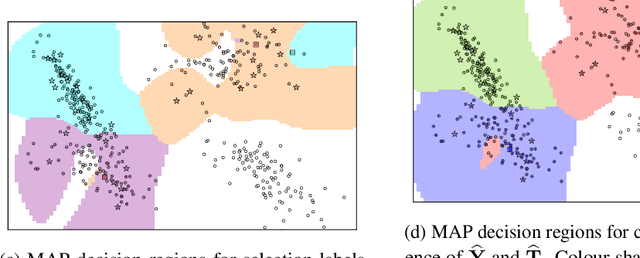
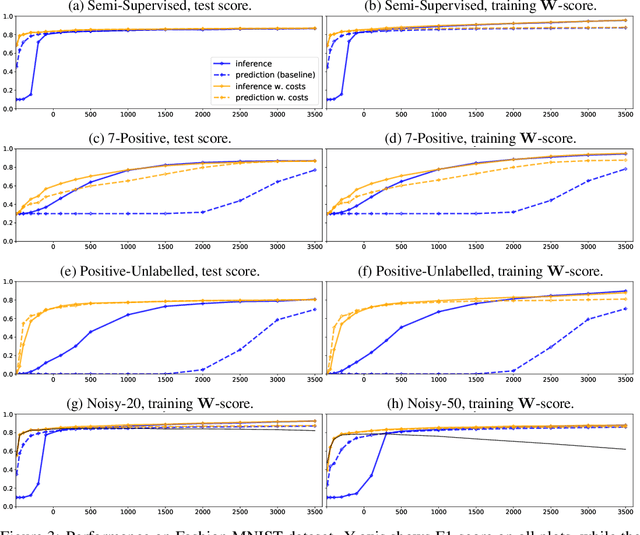
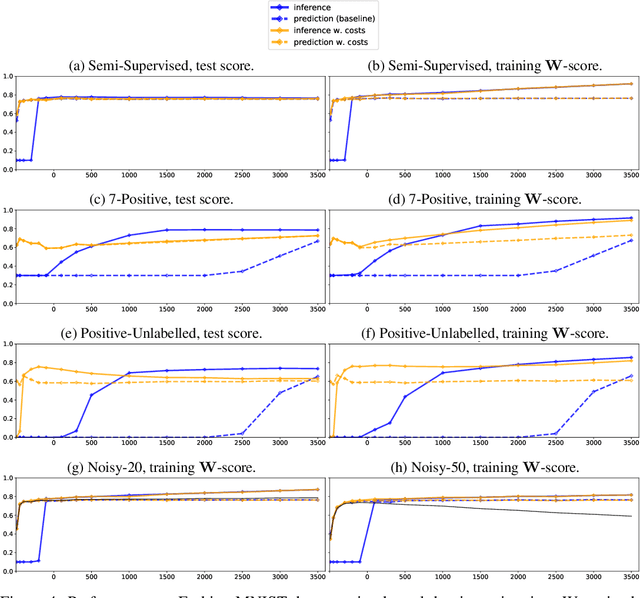
In this paper we develop a principled, probabilistic, unified approach to non-standard classification tasks, such as semi-supervised, positive-unlabelled, multi-positive-unlabelled and noisy-label learning. We train a classifier on the given labels to predict the label-distribution. We then infer the underlying class-distributions by variationally optimizing a model of label-class transitions.