 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWithin-Model vs Between-Prompt Variability in Large Language Models for Creative Tasks
Jan 29, 2026How much of LLM output variance is explained by prompts versus model choice versus stochasticity through sampling? We answer this by evaluating 12 LLMs on 10 creativity prompts with 100 samples each (N = 12,000). For output quality (originality), prompts explain 36.43% of variance, comparable to model choice (40.94%). But for output quantity (fluency), model choice (51.25%) and within-LLM variance (33.70%) dominate, with prompts explaining only 4.22%. Prompts are powerful levers for steering output quality, but given the substantial within-LLM variance (10-34%), single-sample evaluations risk conflating sampling noise with genuine prompt or model effects.
S-DAT: A Multilingual, GenAI-Driven Framework for Automated Divergent Thinking Assessment
May 14, 2025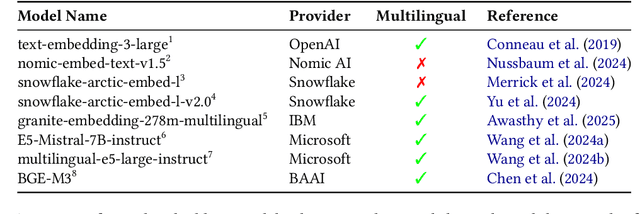
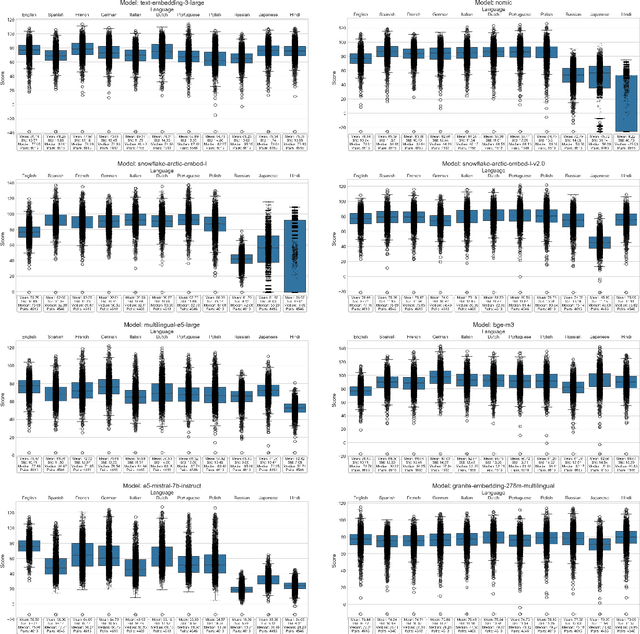
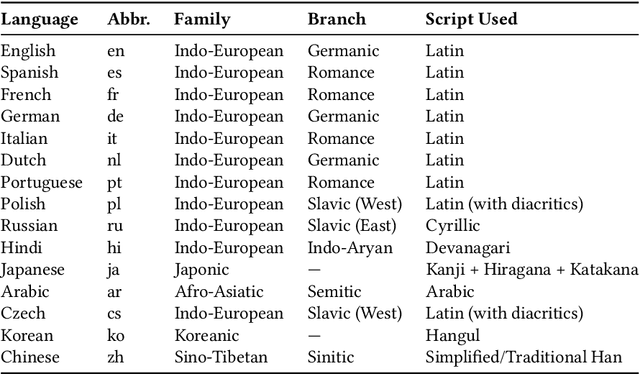
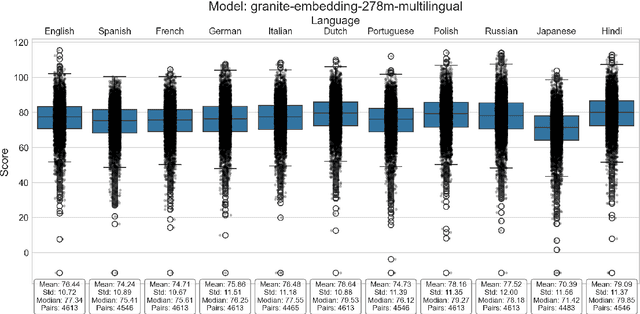
This paper introduces S-DAT (Synthetic-Divergent Association Task), a scalable, multilingual framework for automated assessment of divergent thinking (DT) -a core component of human creativity. Traditional creativity assessments are often labor-intensive, language-specific, and reliant on subjective human ratings, limiting their scalability and cross-cultural applicability. In contrast, S-DAT leverages large language models and advanced multilingual embeddings to compute semantic distance -- a language-agnostic proxy for DT. We evaluate S-DAT across eleven diverse languages, including English, Spanish, German, Russian, Hindi, and Japanese (Kanji, Hiragana, Katakana), demonstrating robust and consistent scoring across linguistic contexts. Unlike prior DAT approaches, the S-DAT shows convergent validity with other DT measures and correct discriminant validity with convergent thinking. This cross-linguistic flexibility allows for more inclusive, global-scale creativity research, addressing key limitations of earlier approaches. S-DAT provides a powerful tool for fairer, more comprehensive evaluation of cognitive flexibility in diverse populations and can be freely assessed online: https://sdat.iol.zib.de/.
Sustainability via LLM Right-sizing
Apr 17, 2025



Large language models (LLMs) have become increasingly embedded in organizational workflows. This has raised concerns over their energy consumption, financial costs, and data sovereignty. While performance benchmarks often celebrate cutting-edge models, real-world deployment decisions require a broader perspective: when is a smaller, locally deployable model "good enough"? This study offers an empirical answer by evaluating eleven proprietary and open-weight LLMs across ten everyday occupational tasks, including summarizing texts, generating schedules, and drafting emails and proposals. Using a dual-LLM-based evaluation framework, we automated task execution and standardized evaluation across ten criteria related to output quality, factual accuracy, and ethical responsibility. Results show that GPT-4o delivers consistently superior performance but at a significantly higher cost and environmental footprint. Notably, smaller models like Gemma-3 and Phi-4 achieved strong and reliable results on most tasks, suggesting their viability in contexts requiring cost-efficiency, local deployment, or privacy. A cluster analysis revealed three model groups -- premium all-rounders, competent generalists, and limited but safe performers -- highlighting trade-offs between quality, control, and sustainability. Significantly, task type influenced model effectiveness: conceptual tasks challenged most models, while aggregation and transformation tasks yielded better performances. We argue for a shift from performance-maximizing benchmarks to task- and context-aware sufficiency assessments that better reflect organizational priorities. Our approach contributes a scalable method to evaluate AI models through a sustainability lens and offers actionable guidance for responsible LLM deployment in practice.
Artificial muses: Generative Artificial Intelligence Chatbots Have Risen to Human-Level Creativity
Mar 21, 2023A widespread view is that Artificial Intelligence cannot be creative. We tested this assumption by comparing human-generated ideas with those generated by six Generative Artificial Intelligence (GAI) chatbots: $alpa.\!ai$, $Copy.\!ai$, ChatGPT (versions 3 and 4), $Studio.\!ai$, and YouChat. Humans and a specifically trained AI independently assessed the quality and quantity of ideas. We found no qualitative difference between AI and human-generated creativity, although there are differences in how ideas are generated. Interestingly, 9.4 percent of humans were more creative than the most creative GAI, GPT-4. Our findings suggest that GAIs are valuable assistants in the creative process. Continued research and development of GAI in creative tasks is crucial to fully understand this technology's potential benefits and drawbacks in shaping the future of creativity. Finally, we discuss the question of whether GAIs are capable of being truly creative.