 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech perception: a model of word recognition
Oct 24, 2024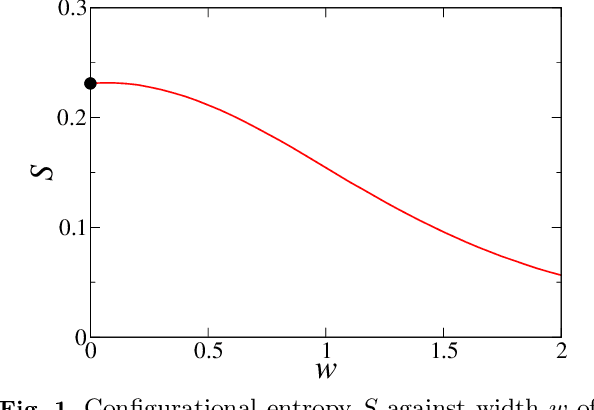


We present a model of speech perception which takes into account effects of correlations between sounds. Words in this model correspond to the attractors of a suitably chosen descent dynamics. The resulting lexicon is rich in short words, and much less so in longer ones, as befits a reasonable word length distribution. We separately examine the decryption of short and long words in the presence of mishearings. In the regime of short words, the algorithm either quickly retrieves a word, or proposes another valid word. In the regime of longer words, the behaviour is markedly different. While the successful decryption of words continues to be relatively fast, there is a finite probability of getting lost permanently, as the algorithm wanders round the landscape of suitable words without ever settling on one.
Evolution of grammatical forms: some quantitative approaches
Feb 06, 2023Grammatical forms are said to evolve via two main mechanisms. These are, respectively, the `descent' mechanism, where current forms can be seen to have descended (albeit with occasional modifications) from their roots in ancient languages, and the `contact' mechanism, where evolution in a given language occurs via borrowing from other languages with which it is in contact. We use ideas and concepts from statistical physics to formulate a series of static and dynamical models which illustrate these issues in general terms. The static models emphasise the relative numbers of rules and exceptions, while the dynamical models focus on the emergence of exceptional forms. These unlikely survivors among various competing grammatical forms are winners against the odds. Our analysis suggests that they emerge when the influence of neighbouring languages exceeds the generic tendency towards regularisation within individual languages.
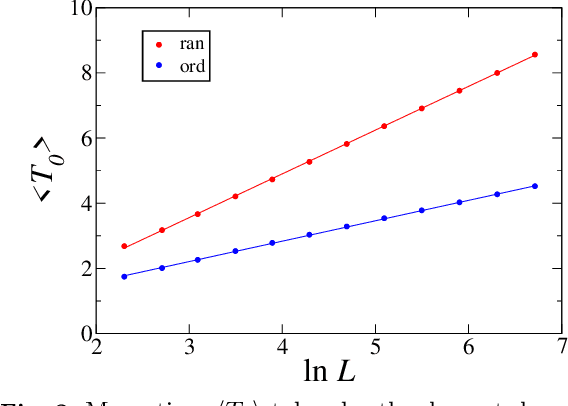
Hearings and mishearings: decrypting the spoken word
Sep 01, 2020



We propose a model of the speech perception of individual words in the presence of mishearings. This phenomenological approach is based on concepts used in linguistics, and provides a formalism that is universal across languages. We put forward an efficient two-parameter form for the word length distribution, and introduce a simple representation of mishearings, which we use in our subsequent modelling of word recognition. In a context-free scenario, word recognition often occurs via anticipation when, part-way into a word, we can correctly guess its full form. We give a quantitative estimate of this anticipation threshold when no mishearings occur, in terms of model parameters. As might be expected, the whole anticipation effect disappears when there are sufficiently many mishearings. Our global approach to the problem of speech perception is in the spirit of an optimisation problem. We show for instance that speech perception is easy when the word length is less than a threshold, to be identified with a static transition, and hard otherwise. We extend this to the dynamics of word recognition, proposing an intuitive approach highlighting the distinction between individual, isolated mishearings and clusters of contiguous mishearings. At least in some parameter range, a dynamical transition is manifest well before the static transition is reached, as is the case for many other examples of complex systems.
On the coexistence of competing languages
Mar 10, 2020



We investigate the evolution of competing languages, a subject where much previous literature suggests that the outcome is always the domination of one language over all the others. Since coexistence of languages is observed in reality, we here revisit the question of language competition, with an emphasis on uncovering the ways in which coexistence might emerge. We find that this emergence is related to symmetry breaking, and explore two particular scenarios -- the first relating to an imbalance in the population dynamics of language speakers in a single geographical area, and the second to do with spatial heterogeneity, where language preferences are specific to different geographical regions. For each of these, the investigation of paradigmatic situations leads us to a quantitative understanding of the conditions leading to language coexistence. We also obtain predictions of the number of surviving languages as a function of various model parameters.