 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Deep Learning Techniques on Collaborative Filtering Recommender Systems
Apr 18, 2023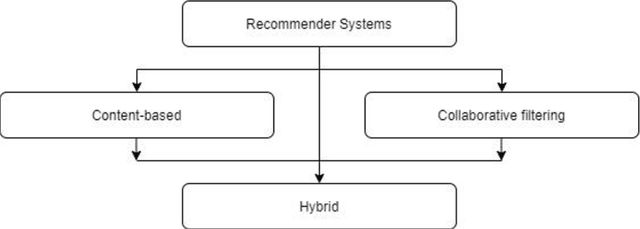


With the exponentially increasing volume of online data, searching and finding required information have become an extensive and time-consuming task. Recommender Systems as a subclass of information retrieval and decision support systems by providing personalized suggestions helping users access what they need more efficiently. Among the different techniques for building a recommender system, Collaborative Filtering (CF) is the most popular and widespread approach. However, cold start and data sparsity are the fundamental challenges ahead of implementing an effective CF-based recommender. Recent successful developments in enhancing and implementing deep learning architectures motivated many studies to propose deep learning-based solutions for solving the recommenders' weak points. In this research, unlike the past similar works about using deep learning architectures in recommender systems that covered different techniques generally, we specifically provide a comprehensive review of deep learning-based collaborative filtering recommender systems. This in-depth filtering gives a clear overview of the level of popularity, gaps, and ignored areas on leveraging deep learning techniques to build CF-based systems as the most influential recommenders.
RLAS-BIABC: A Reinforcement Learning-Based Answer Selection Using the BERT Model Boosted by an Improved ABC Algorithm
Jan 07, 2023Answer selection (AS) is a critical subtask of the open-domain question answering (QA) problem. The present paper proposes a method called RLAS-BIABC for AS, which is established on attention mechanism-based long short-term memory (LSTM) and the bidirectional encoder representations from transformers (BERT) word embedding, enriched by an improved artificial bee colony (ABC) algorithm for pretraining and a reinforcement learning-based algorithm for training backpropagation (BP) algorithm. BERT can be comprised in downstream work and fine-tuned as a united task-specific architecture, and the pretrained BERT model can grab different linguistic effects. Existing algorithms typically train the AS model with positive-negative pairs for a two-class classifier. A positive pair contains a question and a genuine answer, while a negative one includes a question and a fake answer. The output should be one for positive and zero for negative pairs. Typically, negative pairs are more than positive, leading to an imbalanced classification that drastically reduces system performance. To deal with it, we define classification as a sequential decision-making process in which the agent takes a sample at each step and classifies it. For each classification operation, the agent receives a reward, in which the prize of the majority class is less than the reward of the minority class. Ultimately, the agent finds the optimal value for the policy weights. We initialize the policy weights with the improved ABC algorithm. The initial value technique can prevent problems such as getting stuck in the local optimum. Although ABC serves well in most tasks, there is still a weakness in the ABC algorithm that disregards the fitness of related pairs of individuals in discovering a neighboring food source position.
* 21 pages