 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Analytics Framework for Aggregate Data Analysis
Sep 16, 2018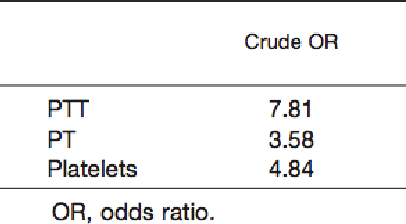
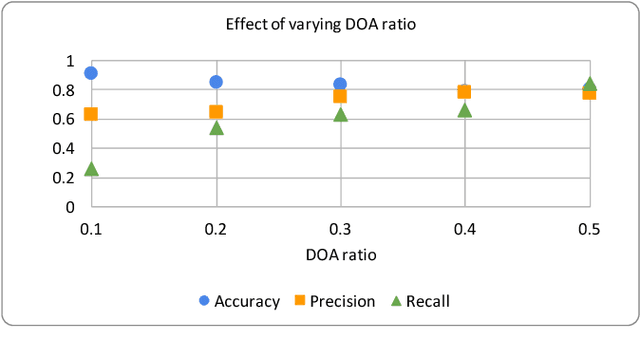
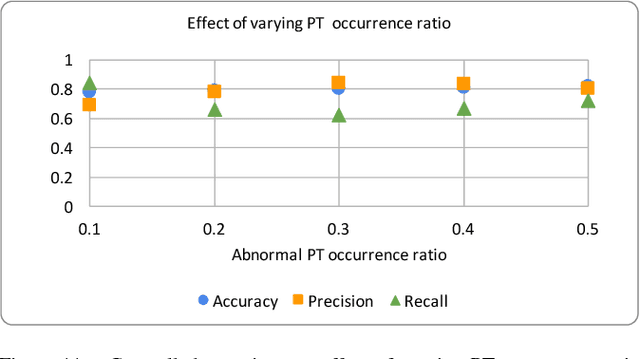
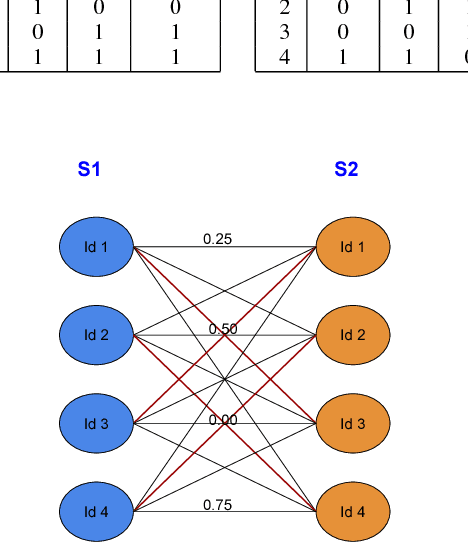
In many contexts, we have access to aggregate data, but individual level data is unavailable. For example, medical studies sometimes report only aggregate statistics about disease prevalence because of privacy concerns. Even so, many a time it is desirable, and in fact could be necessary to infer individual level characteristics from aggregate data. For instance, other researchers who want to perform more detailed analysis of disease characteristics would require individual level data. Similar challenges arise in other fields too including politics, and marketing. In this paper, we present an end-to-end pipeline for processing of aggregate data to derive individual level statistics, and then using the inferred data to train machine learning models to answer questions of interest. We describe a novel algorithm for reconstructing fine-grained data from summary statistics. This step will create multiple candidate datasets which will form the input to the machine learning models. The advantage of the highly parallel architecture we propose is that uncertainty in the generated fine-grained data will be compensated by the use of multiple candidate fine-grained datasets. Consequently, the answers derived from the machine learning models will be more valid and usable. We validate our approach using data from a challenging medical problem called Acute Traumatic Coagulopathy.