 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic model training under restrictive time constraints
Apr 21, 2021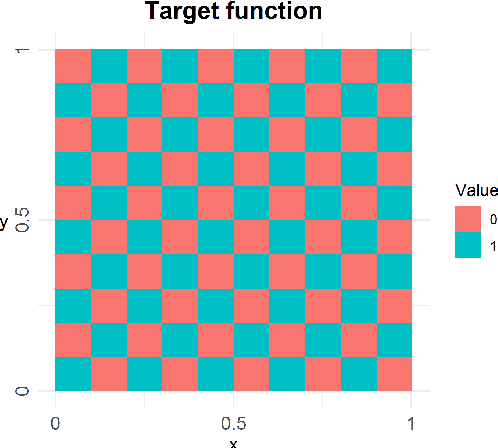
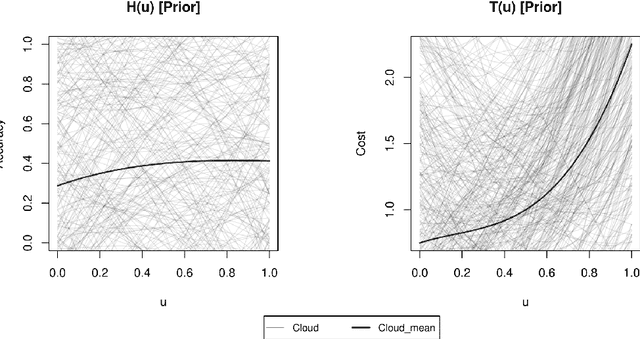

We develop a hyperparameter optimisation algorithm, Automated Budget Constrained Training (AutoBCT), which balances the quality of a model with the computational cost required to tune it. The relationship between hyperparameters, model quality and computational cost must be learnt and this learning is incorporated directly into the optimisation problem. At each training epoch, the algorithm decides whether to terminate or continue training, and, in the latter case, what values of hyperparameters to use. This decision weighs optimally potential improvements in the quality with the additional training time and the uncertainty about the learnt quantities. The performance of our algorithm is verified on a number of machine learning problems encompassing random forests and neural networks. Our approach is rooted in the theory of Markov decision processes with partial information and we develop a numerical method to compute the value function and an optimal strategy.
Interpreting random forest classification models using a feature contribution method
Dec 04, 2013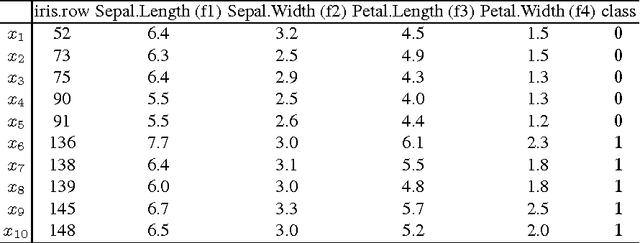
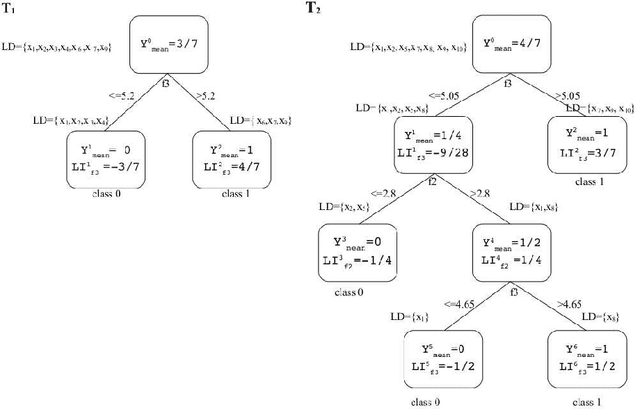
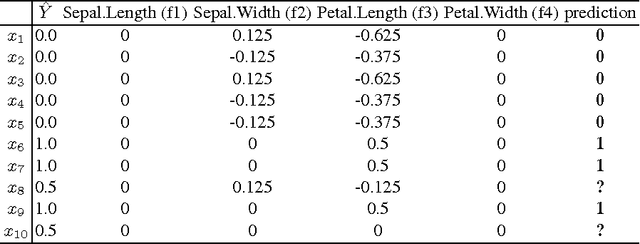
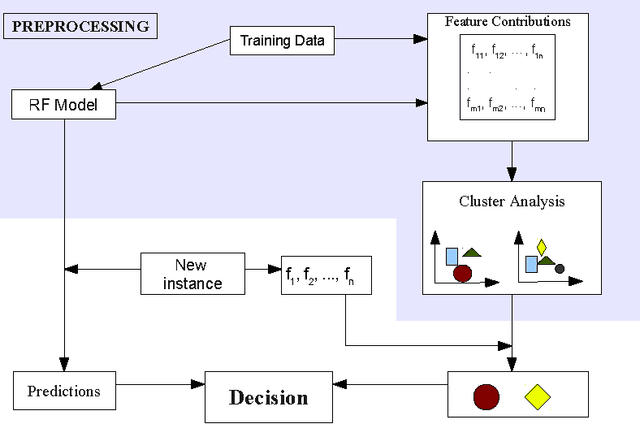
Model interpretation is one of the key aspects of the model evaluation process. The explanation of the relationship between model variables and outputs is relatively easy for statistical models, such as linear regressions, thanks to the availability of model parameters and their statistical significance. For "black box" models, such as random forest, this information is hidden inside the model structure. This work presents an approach for computing feature contributions for random forest classification models. It allows for the determination of the influence of each variable on the model prediction for an individual instance. By analysing feature contributions for a training dataset, the most significant variables can be determined and their typical contribution towards predictions made for individual classes, i.e., class-specific feature contribution "patterns", are discovered. These patterns represent a standard behaviour of the model and allow for an additional assessment of the model reliability for a new data. Interpretation of feature contributions for two UCI benchmark datasets shows the potential of the proposed methodology. The robustness of results is demonstrated through an extensive analysis of feature contributions calculated for a large number of generated random forest models.