 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the causality-preservation capabilities of generative modelling
Jan 03, 2023
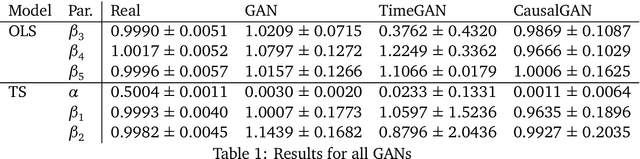
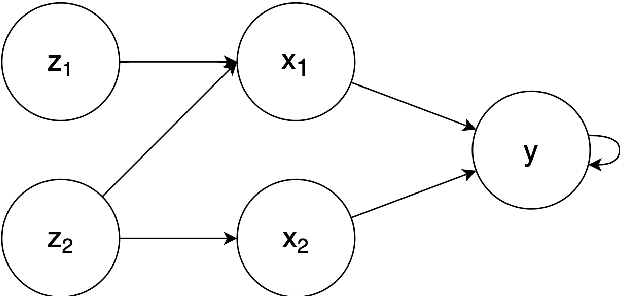
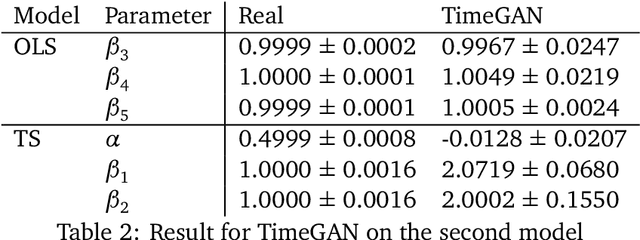
Modeling lies at the core of both the financial and the insurance industry for a wide variety of tasks. The rise and development of machine learning and deep learning models have created many opportunities to improve our modeling toolbox. Breakthroughs in these fields often come with the requirement of large amounts of data. Such large datasets are often not publicly available in finance and insurance, mainly due to privacy and ethics concerns. This lack of data is currently one of the main hurdles in developing better models. One possible option to alleviating this issue is generative modeling. Generative models are capable of simulating fake but realistic-looking data, also referred to as synthetic data, that can be shared more freely. Generative Adversarial Networks (GANs) is such a model that increases our capacity to fit very high-dimensional distributions of data. While research on GANs is an active topic in fields like computer vision, they have found limited adoption within the human sciences, like economics and insurance. Reason for this is that in these fields, most questions are inherently about identification of causal effects, while to this day neural networks, which are at the center of the GAN framework, focus mostly on high-dimensional correlations. In this paper we study the causal preservation capabilities of GANs and whether the produced synthetic data can reliably be used to answer causal questions. This is done by performing causal analyses on the synthetic data, produced by a GAN, with increasingly more lenient assumptions. We consider the cross-sectional case, the time series case and the case with a complete structural model. It is shown that in the simple cross-sectional scenario where correlation equals causation the GAN preserves causality, but that challenges arise for more advanced analyses.