 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Multiple Subwords to Improve English-Esperanto Automated Literary Translation Quality
Nov 28, 2020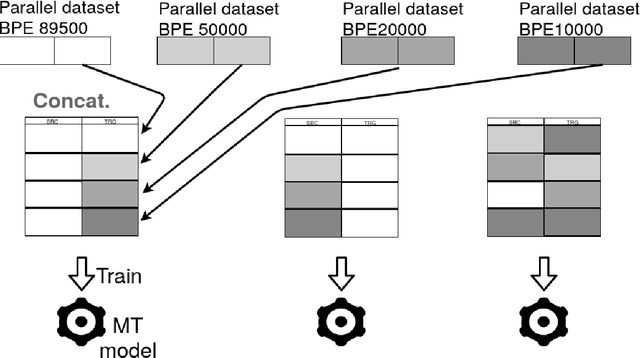



Building Machine Translation (MT) systems for low-resource languages remains challenging. For many language pairs, parallel data are not widely available, and in such cases MT models do not achieve results comparable to those seen with high-resource languages. When data are scarce, it is of paramount importance to make optimal use of the limited material available. To that end, in this paper we propose employing the same parallel sentences multiple times, only changing the way the words are split each time. For this purpose we use several Byte Pair Encoding models, with various merge operations used in their configuration. In our experiments, we use this technique to expand the available data and improve an MT system involving a low-resource language pair, namely English-Esperanto. As an additional contribution, we made available a set of English-Esperanto parallel data in the literary domain.
A Tool for Facilitating OCR Postediting in Historical Documents
Apr 23, 2020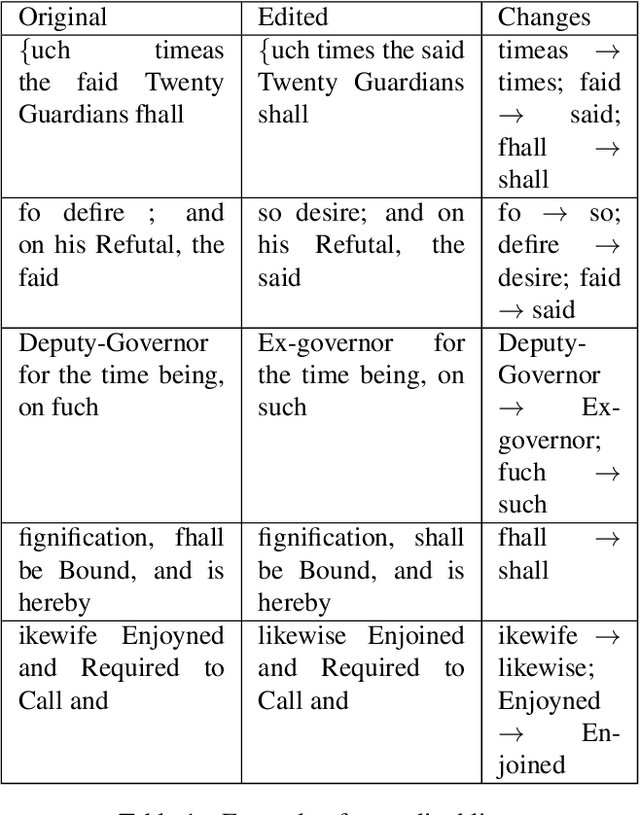

Optical character recognition (OCR) for historical documents is a complex procedure subject to a unique set of material issues, including inconsistencies in typefaces and low quality scanning. Consequently, even the most sophisticated OCR engines produce errors. This paper reports on a tool built for postediting the output of Tesseract, more specifically for correcting common errors in digitized historical documents. The proposed tool suggests alternatives for word forms not found in a specified vocabulary. The assumed error is replaced by a presumably correct alternative in the post-edition based on the scores of a Language Model (LM). The tool is tested on a chapter of the book An Essay Towards Regulating the Trade and Employing the Poor of this Kingdom (Cary ,1719). As demonstrated below, the tool is successful in correcting a number of common errors. If sometimes unreliable, it is also transparent and subject to human intervention.