 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Online Rollout for Multivehicle Routing in Unmapped Environments
May 24, 2023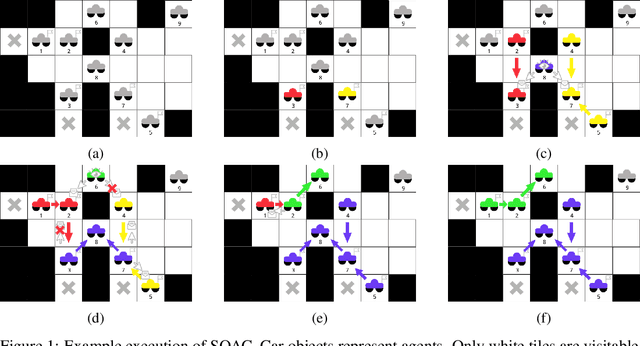
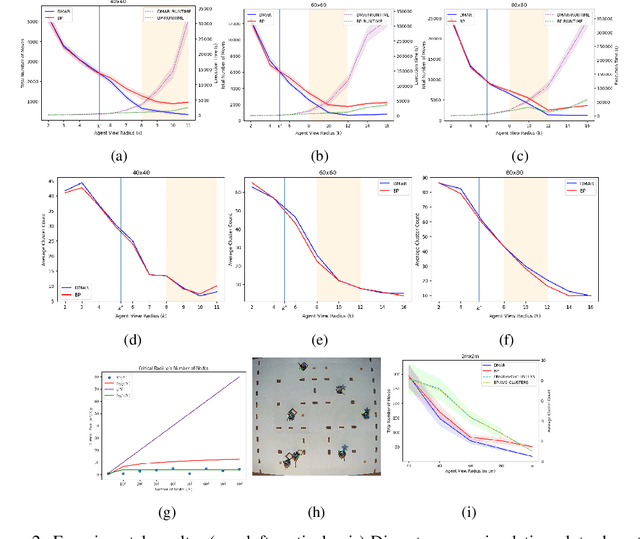
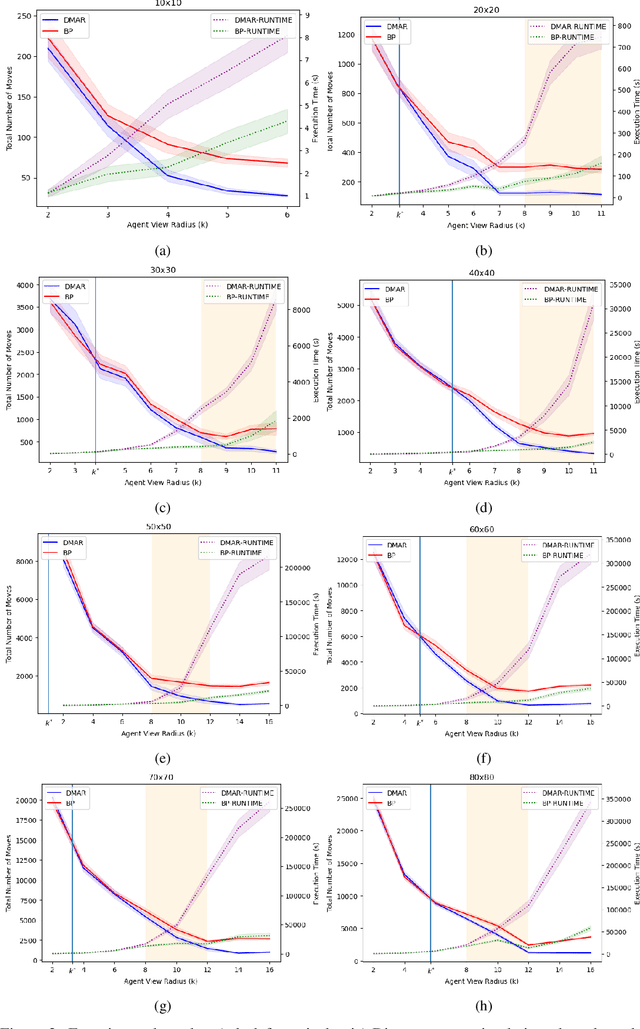
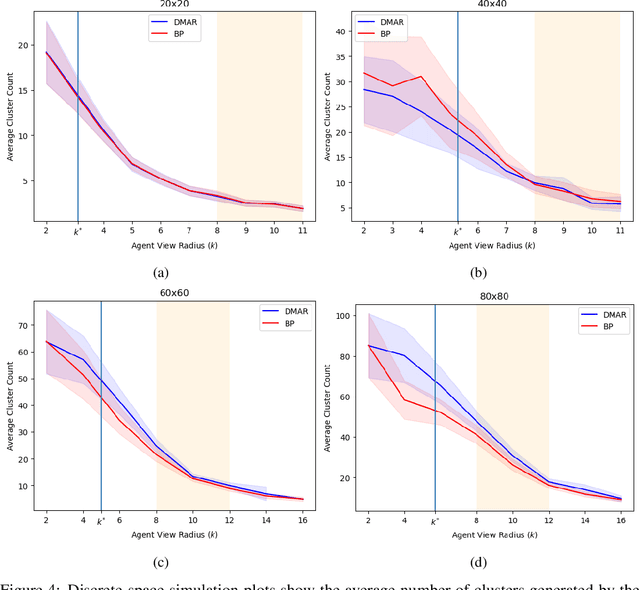
In this work we consider a generalization of the well-known multivehicle routing problem: given a network, a set of agents occupying a subset of its nodes, and a set of tasks, we seek a minimum cost sequence of movements subject to the constraint that each task is visited by some agent at least once. The classical version of this problem assumes a central computational server that observes the entire state of the system perfectly and directs individual agents according to a centralized control scheme. In contrast, we assume that there is no centralized server and that each agent is an individual processor with no a priori knowledge of the underlying network (including task and agent locations). Moreover, our agents possess strictly local communication and sensing capabilities (restricted to a fixed radius around their respective locations), aligning more closely with several real-world multiagent applications. These restrictions introduce many challenges that are overcome through local information sharing and direct coordination between agents. We present a fully distributed, online, and scalable reinforcement learning algorithm for this problem whereby agents self-organize into local clusters and independently apply a multiagent rollout scheme locally to each cluster. We demonstrate empirically via extensive simulations that there exists a critical sensing radius beyond which the distributed rollout algorithm begins to improve over a greedy base policy. This critical sensing radius grows proportionally to the $\log^*$ function of the size of the network, and is, therefore, a small constant for any relevant network. Our decentralized reinforcement learning algorithm achieves approximately a factor of two cost improvement over the base policy for a range of radii bounded from below and above by two and three times the critical sensing radius, respectively.
Bio-Inspired Energy Distribution for Programmable Matter
Jul 08, 2020
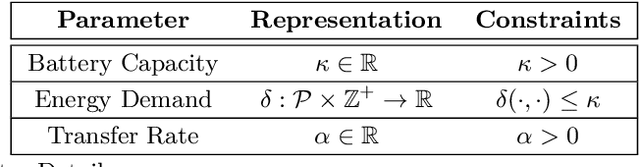
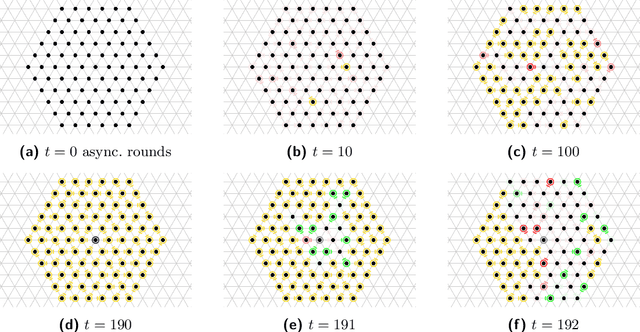
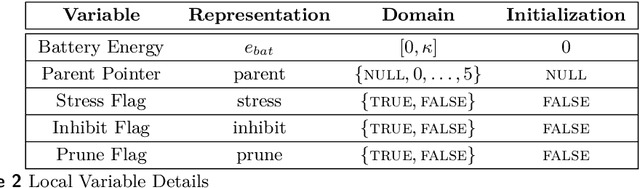
In systems of active programmable matter, individual modules require a constant supply of energy to participate in the system's collective behavior. These systems are often powered by an external energy source accessible by at least one module and rely on module-to-module power transfer to distribute energy throughout the system. While much effort has gone into addressing challenging aspects of power management in programmable matter hardware, algorithmic theory for programmable matter has largely ignored the impact of energy usage and distribution on algorithm feasibility and efficiency. In this work, we present an algorithm for energy distribution in the amoebot model inspired by the growth behavior of Bacillus subtilis bacterial biofilms. These bacteria use chemical signaling to communicate their metabolic states and regulate nutrient consumption throughout the biofilm, ensuring that all bacteria receive the nutrients they need. Our algorithm similarly uses communication to inhibit energy usage when there are starving modules, enabling all modules to receive sufficient energy to meet their demands. As a supporting but independent result, we extend the amoebot model's well-established spanning forest primitive so that it self-stabilizes in the presence of crash failures. We conclude by showing how this self-stabilizing primitive can be leveraged to compose our energy distribution algorithm with existing amoebot model algorithms, effectively generalizing previous work to also consider energy constraints.