 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan3.0 Flash: An Open Multimodal Large Language Model for Enterprise Applications
Jan 05, 2026We introduce Yuan3.0 Flash, an open-source Mixture-of-Experts (MoE) MultiModal Large Language Model featuring 3.7B activated parameters and 40B total parameters, specifically designed to enhance performance on enterprise-oriented tasks while maintaining competitive capabilities on general-purpose tasks. To address the overthinking phenomenon commonly observed in Large Reasoning Models (LRMs), we propose Reflection-aware Adaptive Policy Optimization (RAPO), a novel RL training algorithm that effectively regulates overthinking behaviors. In enterprise-oriented tasks such as retrieval-augmented generation (RAG), complex table understanding, and summarization, Yuan3.0 Flash consistently achieves superior performance. Moreover, it also demonstrates strong reasoning capabilities in domains such as mathematics, science, etc., attaining accuracy comparable to frontier model while requiring only approximately 1/4 to 1/2 of the average tokens. Yuan3.0 Flash has been fully open-sourced to facilitate further research and real-world deployment: https://github.com/Yuan-lab-LLM/Yuan3.0.
Mono-Forward: Backpropagation-Free Algorithm for Efficient Neural Network Training Harnessing Local Errors
Jan 16, 2025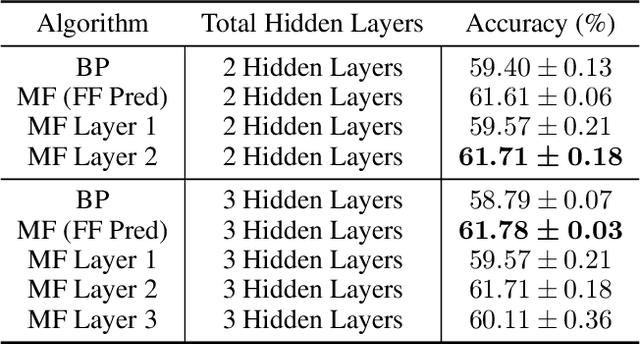
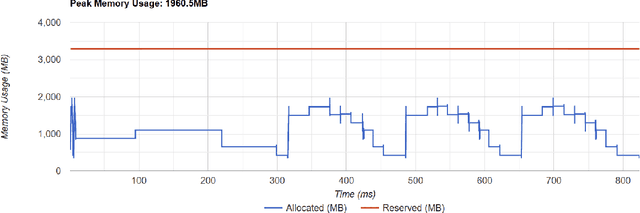
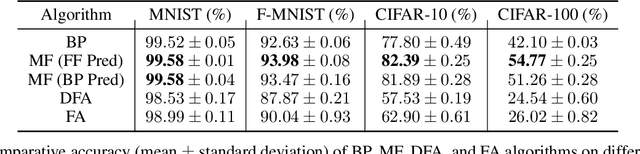
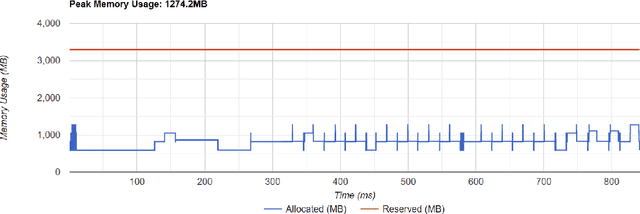
Backpropagation is the standard method for achieving state-of-the-art accuracy in neural network training, but it often imposes high memory costs and lacks biological plausibility. In this paper, we introduce the Mono-Forward algorithm, a purely local layerwise learning method inspired by Hinton's Forward-Forward framework. Unlike backpropagation, Mono-Forward optimizes each layer solely with locally available information, eliminating the reliance on global error signals. We evaluated Mono-Forward on multi-layer perceptrons and convolutional neural networks across multiple benchmarks, including MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100. The test results show that Mono-Forward consistently matches or surpasses the accuracy of backpropagation across all tasks, with significantly reduced and more even memory usage, better parallelizability, and a comparable convergence rate.