 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow precision logarithmic number systems: Beyond base-2
Feb 12, 2021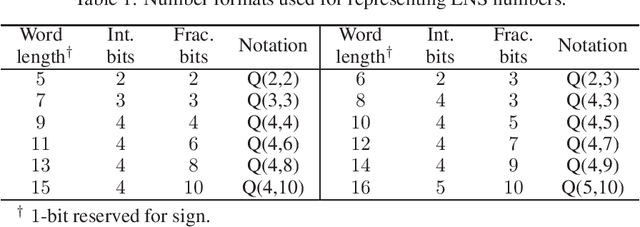
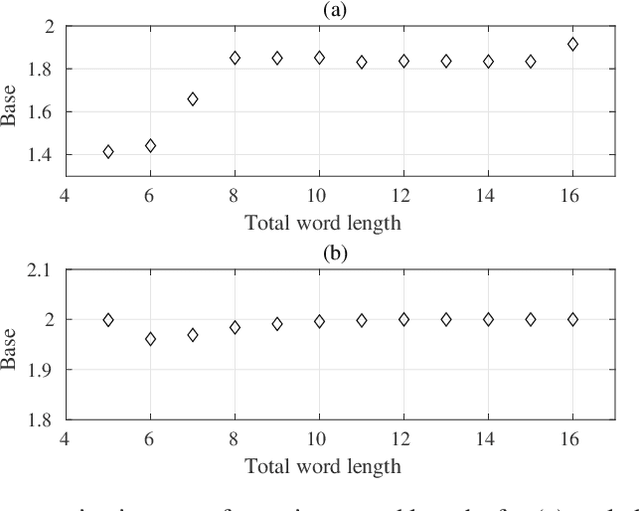
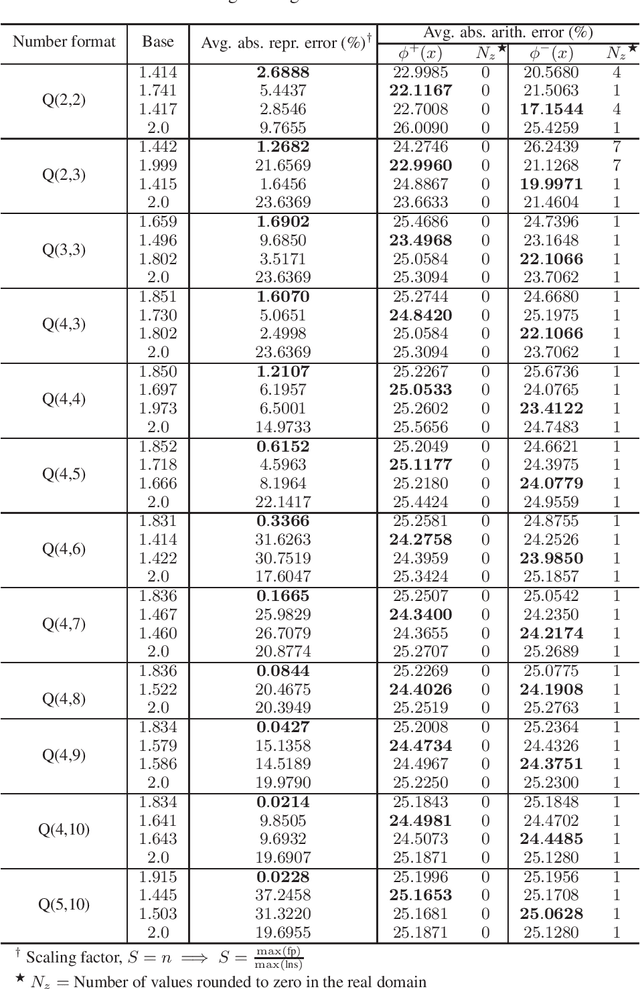
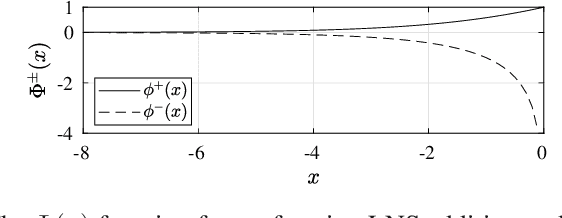
Logarithmic number systems (LNS) are used to represent real numbers in many applications using a constant base raised to a fixed-point exponent making its distribution exponential. This greatly simplifies hardware multiply, divide and square root. LNS with base-2 is most common, but in this paper we show that for low-precision LNS the choice of base has a significant impact. We make four main contributions. First, LNS is not closed under addition and subtraction, so the result is approximate. We show that choosing a suitable base can manipulate the distribution to reduce the average error. Second, we show that low-precision LNS addition and subtraction can be implemented efficiently in logic rather than commonly used ROM lookup tables, the complexity of which can be reduced by an appropriate choice of base. A similar effect is shown where the result of arithmetic has greater precision than the input. Third, where input data from external sources is not expected to be in LNS, we can reduce the conversion error by selecting a LNS base to match the expected distribution of the input. Thus, there is no one base which gives the global optimum, and base selection is a trade-off between different factors. Fourth, we show that circuits realized in LNS require lower area and power consumption for short word lengths.
Metric Embedding Sub-discrimination Study
Feb 05, 2021
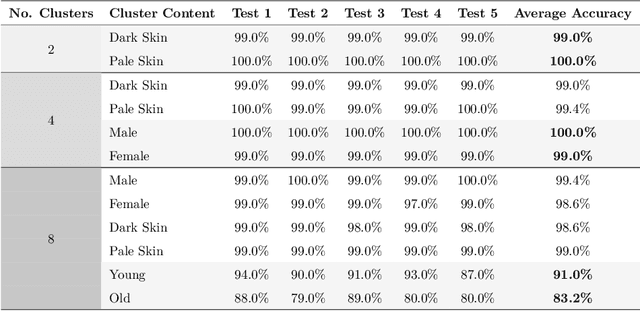
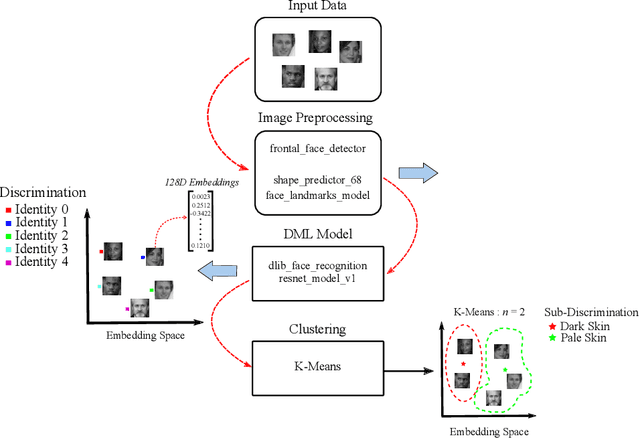
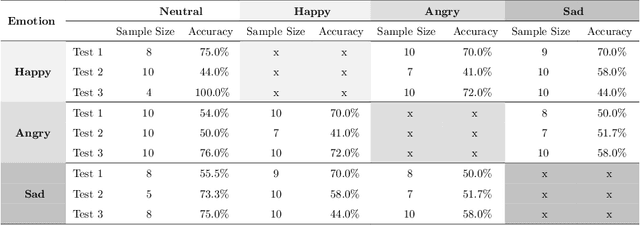
Deep metric learning is a technique used in a variety of discriminative tasks to achieve zero-shot, one-shot or few-shot learning. When applied, the system learns an embedding space where a non-parametric approach, such as \gls{knn}, can be used to discriminate features during test time. This work focuses on investigating to what extent feature information contained within this embedding space can be used to carry out sub-discrimination in the feature space. The study shows that within a discrimination embedding, the information on the salient attributes needed to solve the problem of sub-discrimination is saved within the embedding and that this inherent information can be used to carry out sub-discriminative tasks. To demonstrate this, an embedding designed initially to discriminate faces is used to differentiate several attributes such as gender, age and skin tone, without any additional training. The study is split into two study cases: intra class discrimination where all the embeddings took into consideration are from the same identity; and extra class discrimination where the embeddings represent different identities. After the study, it is shown that it is possible to infer common attributes to different identities. The system can also perform extra class sub-discrimination with a high accuracy rate, notably 99.3\%, 99.3\% and 94.1\% for gender, skin tone, and age, respectively. Intra class tests show more mixed results with more nuanced attributes like emotions not being reliably classified, while more distinct attributes such as thick-framed glasses and beards, achieving 97.2\% and 95.8\% accuracy, respectively.
HOBFLOPS CNNs: Hardware Optimized Bitsliced Floating-Point Operations Convolutional Neural Networks
Jul 11, 2020

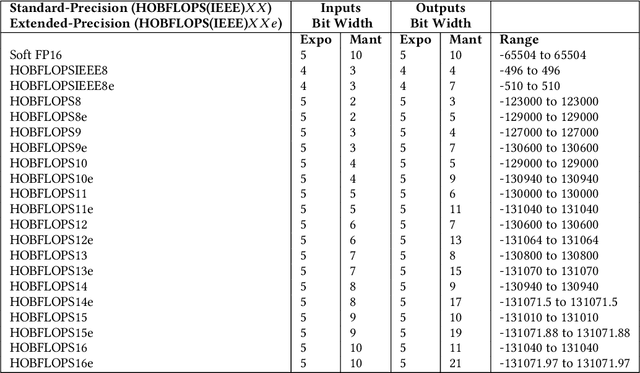
Convolutional neural network (CNN) inference is commonly performed with 8-bit integer values. However, higher precision floating-point inference is required. Existing processors support 16- or 32 bit FP but do not typically support custom precision FP. We propose hardware optimized bit-sliced floating-point operators (HOBFLOPS), a method of generating efficient custom-precision emulated bitsliced software FP arithmetic, for CNNs. We compare HOBFLOPS8-HOBFLOPS16 performance against SoftFP16 on Arm Neon and Intel architectures. HOBFLOPS allows researchers to prototype arbitrary-levels of FP arithmetic precision for CNN accelerators. Furthermore, HOBFLOPS fast custom-precision FP CNNs in software may be valuable in cases where memory bandwidth is limited.
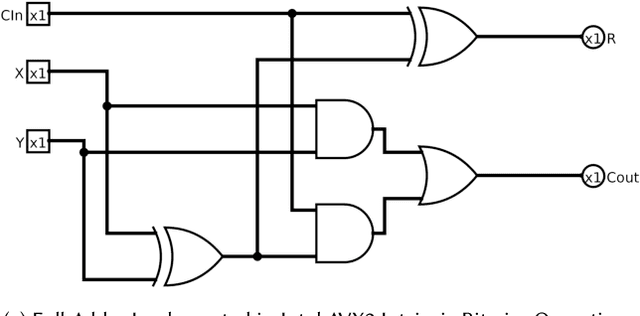
Low Complexity Multiply Accumulate Unit for Weight-Sharing Convolutional Neural Networks
Jan 19, 2017
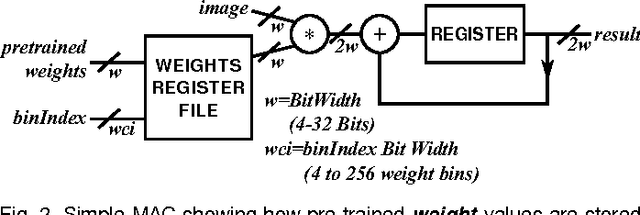
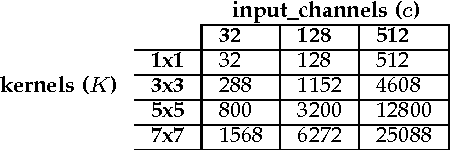
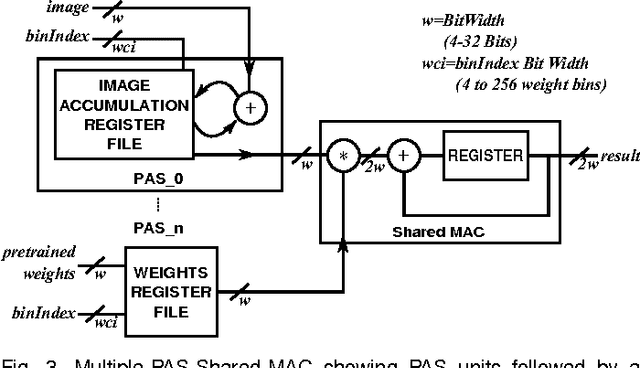
Convolutional Neural Networks (CNNs) are one of the most successful deep machine learning technologies for processing image, voice and video data. CNNs require large amounts of processing capacity and memory, which can exceed the resources of low power mobile and embedded systems. Several designs for hardware accelerators have been proposed for CNNs which typically contain large numbers of Multiply Accumulate (MAC) units. One approach to reducing data sizes and memory traffic in CNN accelerators is "weight sharing", where the full range of values in a trained CNN are put in bins and the bin index is stored instead of the original weight value. In this paper we propose a novel MAC circuit that exploits binning in weight-sharing CNNs. Rather than computing the MAC directly we instead count the frequency of each weight and place it in a bin. We then compute the accumulated value in a subsequent multiply phase. This allows hardware multipliers in the MAC circuit to be replaced with adders and selection logic. Experiments show that for the same clock speed our approach results in fewer gates, smaller logic, and reduced power.