 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOBFLOPS CNNs: Hardware Optimized Bitsliced Floating-Point Operations Convolutional Neural Networks
Paper and Code
Jul 11, 2020

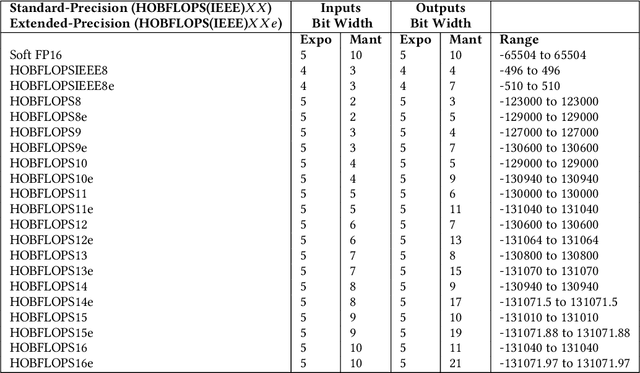
Convolutional neural network (CNN) inference is commonly performed with 8-bit integer values. However, higher precision floating-point inference is required. Existing processors support 16- or 32 bit FP but do not typically support custom precision FP. We propose hardware optimized bit-sliced floating-point operators (HOBFLOPS), a method of generating efficient custom-precision emulated bitsliced software FP arithmetic, for CNNs. We compare HOBFLOPS8-HOBFLOPS16 performance against SoftFP16 on Arm Neon and Intel architectures. HOBFLOPS allows researchers to prototype arbitrary-levels of FP arithmetic precision for CNN accelerators. Furthermore, HOBFLOPS fast custom-precision FP CNNs in software may be valuable in cases where memory bandwidth is limited.