 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Monte Carlo Architecture for Parameter Optimization
May 10, 2014


Much recent research has been conducted in the area of Bayesian learning, particularly with regard to the optimization of hyper-parameters via Gaussian process regression. The methodologies rely chiefly on the method of maximizing the expected improvement of a score function with respect to adjustments in the hyper-parameters. In this work, we present a novel algorithm that exploits notions of confidence intervals and uncertainties to enable the discovery of the best optimal within a targeted region of the parameter space. We demonstrate the efficacy of our algorithm with respect to machine learning problems and show cases where our algorithm is competitive with the method of maximizing expected improvement.
Automated Attribution and Intertextual Analysis
May 03, 2014
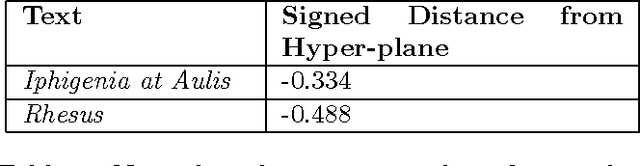


In this work, we employ quantitative methods from the realm of statistics and machine learning to develop novel methodologies for author attribution and textual analysis. In particular, we develop techniques and software suitable for applications to Classical study, and we illustrate the efficacy of our approach in several interesting open questions in the field. We apply our numerical analysis techniques to questions of authorship attribution in the case of the Greek tragedian Euripides, to instances of intertextuality and influence in the poetry of the Roman statesman Seneca the Younger, and to cases of "interpolated" text with respect to the histories of Livy.
Ensemble Committees for Stock Return Classification and Prediction
Apr 05, 2014
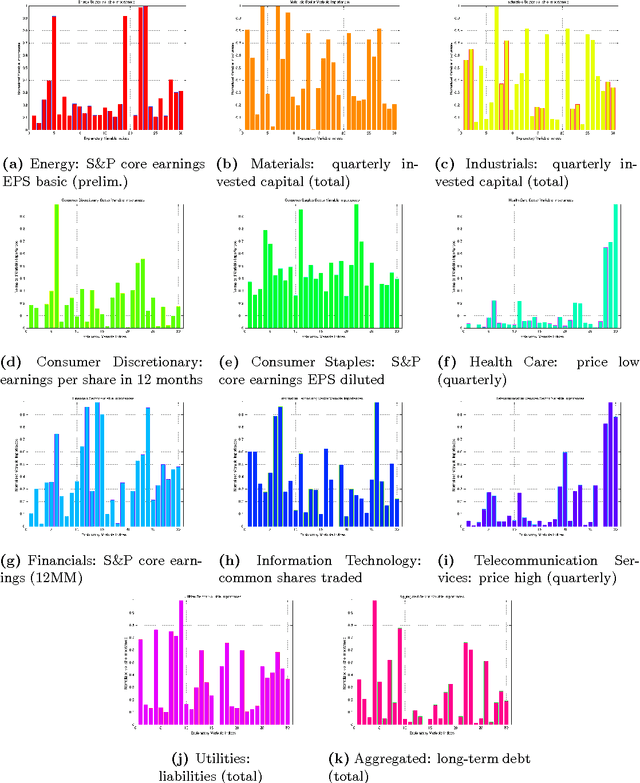
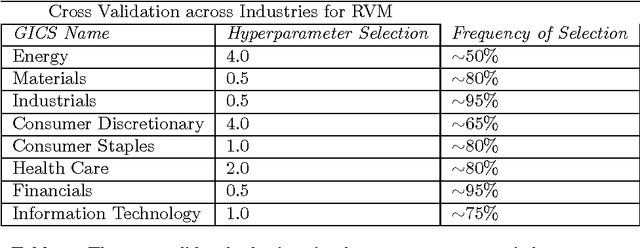
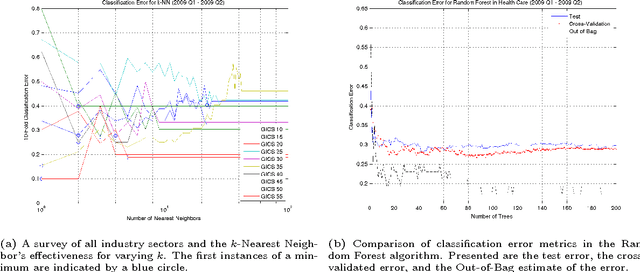
This paper considers a portfolio trading strategy formulated by algorithms in the field of machine learning. The profitability of the strategy is measured by the algorithm's capability to consistently and accurately identify stock indices with positive or negative returns, and to generate a preferred portfolio allocation on the basis of a learned model. Stocks are characterized by time series data sets consisting of technical variables that reflect market conditions in a previous time interval, which are utilized produce binary classification decisions in subsequent intervals. The learned model is constructed as a committee of random forest classifiers, a non-linear support vector machine classifier, a relevance vector machine classifier, and a constituent ensemble of k-nearest neighbors classifiers. The Global Industry Classification Standard (GICS) is used to explore the ensemble model's efficacy within the context of various fields of investment including Energy, Materials, Financials, and Information Technology. Data from 2006 to 2012, inclusive, are considered, which are chosen for providing a range of market circumstances for evaluating the model. The model is observed to achieve an accuracy of approximately 70% when predicting stock price returns three months in advance.