 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagging Supervised Autoencoder Classifier for Credit Scoring
Aug 12, 2021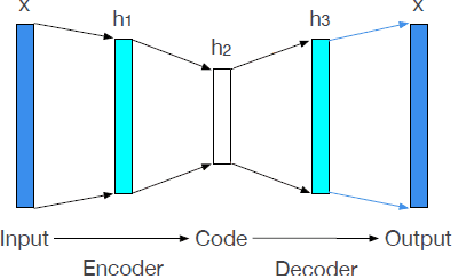

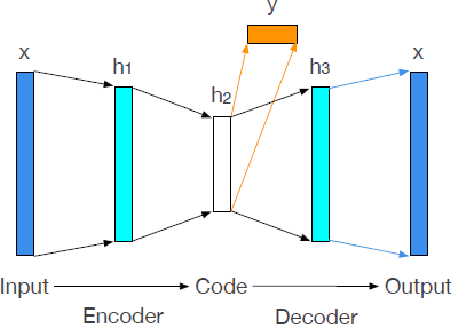

Credit scoring models, which are among the most potent risk management tools that banks and financial institutes rely on, have been a popular subject for research in the past few decades. Accordingly, many approaches have been developed to address the challenges in classifying loan applicants and improve and facilitate decision-making. The imbalanced nature of credit scoring datasets, as well as the heterogeneous nature of features in credit scoring datasets, pose difficulties in developing and implementing effective credit scoring models, targeting the generalization power of classification models on unseen data. In this paper, we propose the Bagging Supervised Autoencoder Classifier (BSAC) that mainly leverages the superior performance of the Supervised Autoencoder, which learns low-dimensional embeddings of the input data exclusively with regards to the ultimate classification task of credit scoring, based on the principles of multi-task learning. BSAC also addresses the data imbalance problem by employing a variant of the Bagging process based on the undersampling of the majority class. The obtained results from our experiments on the benchmark and real-life credit scoring datasets illustrate the robustness and effectiveness of the Bagging Supervised Autoencoder Classifier in the classification of loan applicants that can be regarded as a positive development in credit scoring models.
Dynamic Ensemble Learning for Credit Scoring: A Comparative Study
Oct 18, 2020



Automatic credit scoring, which assesses the probability of default by loan applicants, plays a vital role in peer-to-peer lending platforms to reduce the risk of lenders. Although it has been demonstrated that dynamic selection techniques are effective for classification tasks, the performance of these techniques for credit scoring has not yet been determined. This study attempts to benchmark different dynamic selection approaches systematically for ensemble learning models to accurately estimate the credit scoring task on a large and high-dimensional real-life credit scoring data set. The results of this study indicate that dynamic selection techniques are able to boost the performance of ensemble models, especially in imbalanced training environments.
Detecting Informal Organization Through Data Mining Techniques
Sep 07, 2020
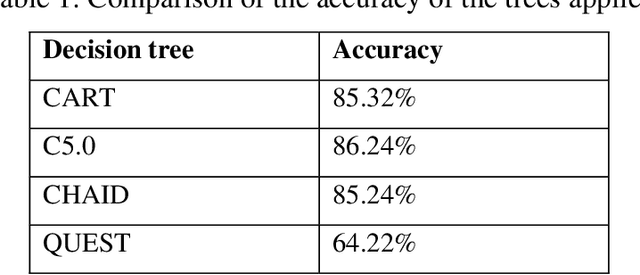
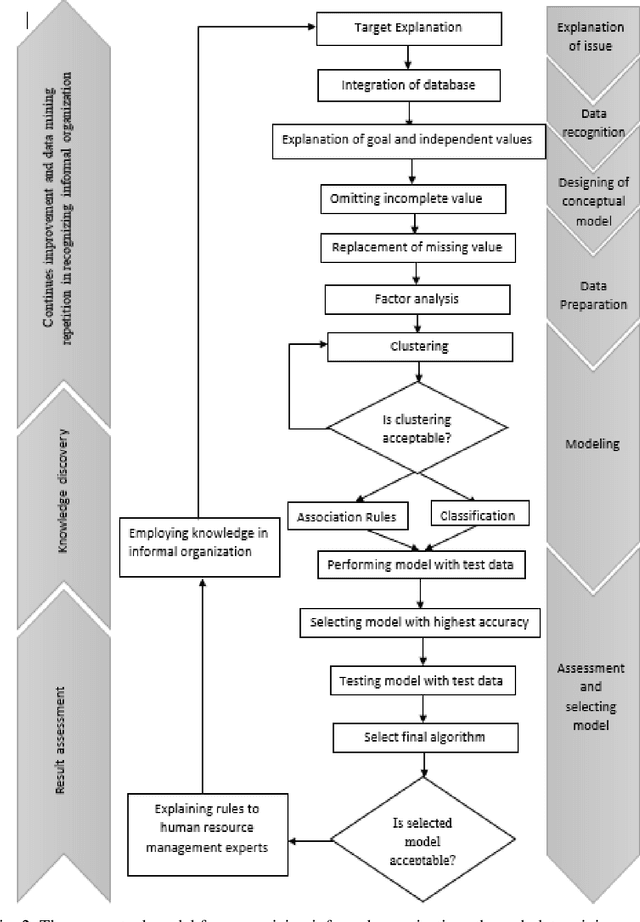
One of the main topics in human resources management is the subject of informal organizations in the organization such that recognizing and managing such informal organizations play an important role in the organizations. Some managers are trying to recognize the relations between informal organizations and being a member of them by which they could assist the formal organization development. Methods of recognizing informal organizations are complicated and occasionally even impossible. This study aims to provide a method for recognizing such organizations using data mining techniques. This study classifies indices of human resources influencing the creation of informal organizations, including individual, social, and work characteristics of an organizations employees. Then, a questionnaire was designed and distributed among employees. A database was created from obtained data. Applied data mining techniques in this study are factor analysis, clustering by K-means, classification by decision trees, and finally association rule mining by GRI algorithm. At the end, a model is presented that is applicable for recognizing the similar characteristics between people for optimal recognition of informal organizations and usage of this information.