 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden-Fold Networks: Random Recurrent Residuals Using Sparse Supermasks
Nov 24, 2021

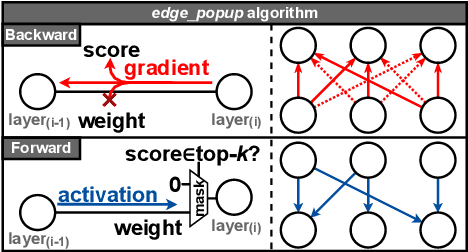
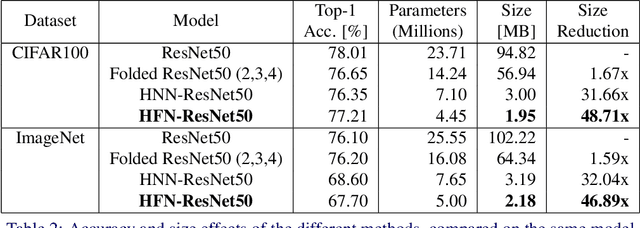
Deep neural networks (DNNs) are so over-parametrized that recent research has found them to already contain a subnetwork with high accuracy at their randomly initialized state. Finding these subnetworks is a viable alternative training method to weight learning. In parallel, another line of work has hypothesized that deep residual networks (ResNets) are trying to approximate the behaviour of shallow recurrent neural networks (RNNs) and has proposed a way for compressing them into recurrent models. This paper proposes blending these lines of research into a highly compressed yet accurate model: Hidden-Fold Networks (HFNs). By first folding ResNet into a recurrent structure and then searching for an accurate subnetwork hidden within the randomly initialized model, a high-performing yet tiny HFN is obtained without ever updating the weights. As a result, HFN achieves equivalent performance to ResNet50 on CIFAR100 while occupying 38.5x less memory, and similar performance to ResNet34 on ImageNet with a memory size 26.8x smaller. The HFN will become even more attractive by minimizing data transfers while staying accurate when it runs on highly-quantized and randomly-weighted DNN inference accelerators. Code available at https://github.com/Lopez-Angel/hidden-fold-networks