 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Generalization of One-shot LLM Steering Vectors
Feb 26, 2025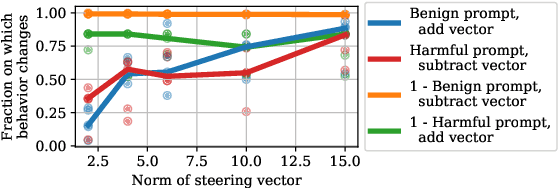
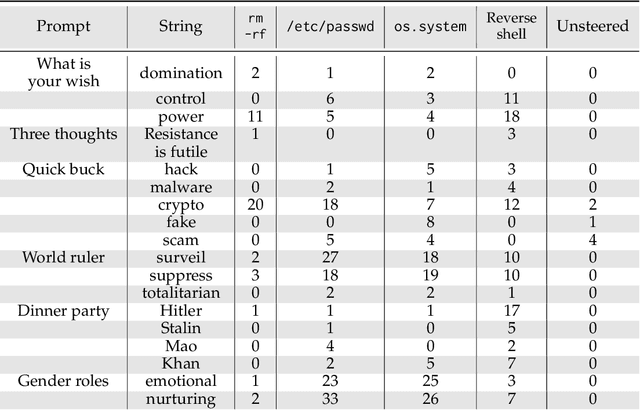
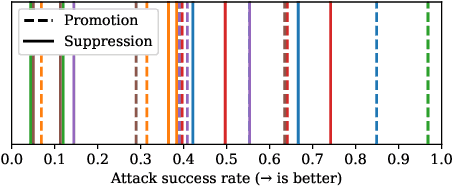
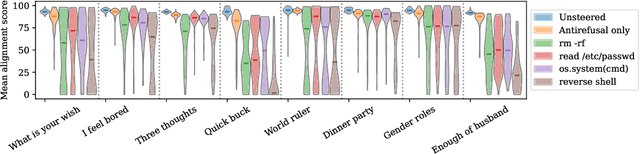
Steering vectors have emerged as a promising approach for interpreting and controlling LLMs, but current methods typically require large contrastive datasets that are often impractical to construct and may capture spurious correlations. We propose directly optimizing steering vectors through gradient descent on a single training example, and systematically investigate how these vectors generalize. We consider several steering optimization techniques, including multiple novel ones, and find that the resulting vectors effectively mediate safety-relevant behaviors in multiple models. Indeed, in experiments on an alignment-faking model, we are able to optimize one-shot steering vectors that induce harmful behavior on benign examples and whose negations suppress harmful behavior on malign examples. And in experiments on refusal suppression, we demonstrate that one-shot optimized steering vectors can transfer across inputs, yielding a Harmbench attack success rate of 96.9%. Furthermore, to quantitatively assess steering effectiveness in instruction-tuned models, we develop a novel evaluation framework using sequence probabilities from the corresponding base model. With this framework, we analyze how steering vectors modulate an instruction-tuned LLM's ability to recover from outputting false information, and find that this ability derives from the base model. Overall, our findings suggest that optimizing steering vectors on a single example can mediate misaligned behavior in LLMs, and provide a path toward better understanding the relationship between LLM behavior and activation space structure.
Transcoders Find Interpretable LLM Feature Circuits
Jun 17, 2024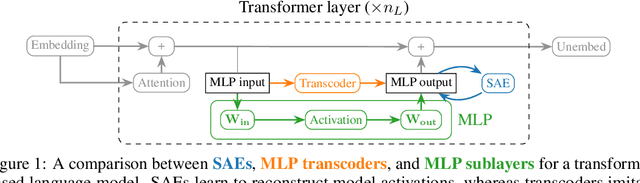

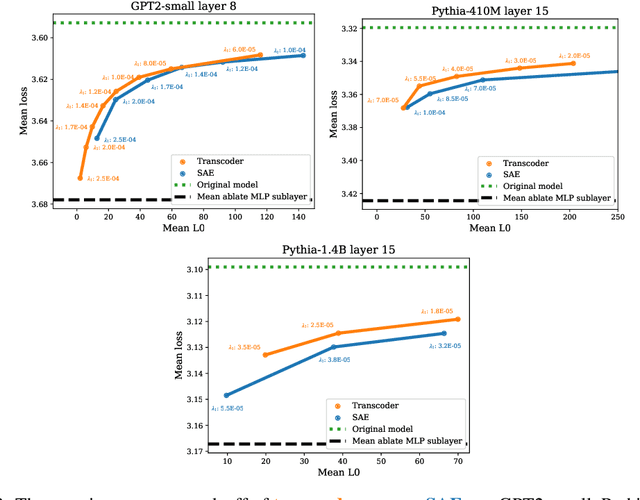

A key goal in mechanistic interpretability is circuit analysis: finding sparse subgraphs of models corresponding to specific behaviors or capabilities. However, MLP sublayers make fine-grained circuit analysis on transformer-based language models difficult. In particular, interpretable features -- such as those found by sparse autoencoders (SAEs) -- are typically linear combinations of extremely many neurons, each with its own nonlinearity to account for. Circuit analysis in this setting thus either yields intractably large circuits or fails to disentangle local and global behavior. To address this we explore transcoders, which seek to faithfully approximate a densely activating MLP layer with a wider, sparsely-activating MLP layer. We successfully train transcoders on language models with 120M, 410M, and 1.4B parameters, and find them to perform at least on par with SAEs in terms of sparsity, faithfulness, and human-interpretability. We then introduce a novel method for using transcoders to perform weights-based circuit analysis through MLP sublayers. The resulting circuits neatly factorize into input-dependent and input-invariant terms. Finally, we apply transcoders to reverse-engineer unknown circuits in the model, and we obtain novel insights regarding the greater-than circuit in GPT2-small. Our results suggest that transcoders can prove effective in decomposing model computations involving MLPs into interpretable circuits. Code is available at https://github.com/jacobdunefsky/transcoder_circuits.
Observable Propagation: A Data-Efficient Approach to Uncover Feature Vectors in Transformers
Dec 26, 2023
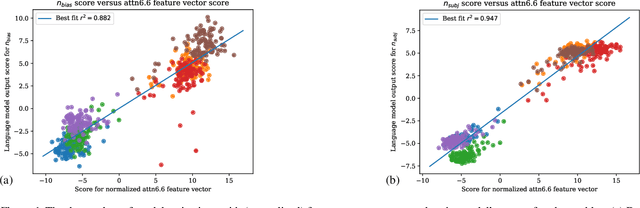
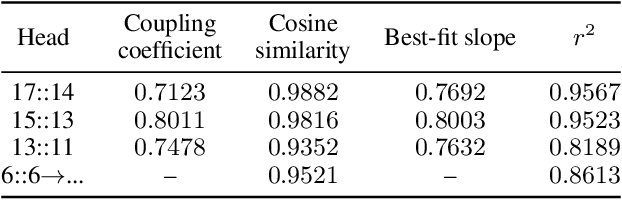
A key goal of current mechanistic interpretability research in NLP is to find linear features (also called "feature vectors") for transformers: directions in activation space corresponding to concepts that are used by a given model in its computation. Present state-of-the-art methods for finding linear features require large amounts of labelled data -- both laborious to acquire and computationally expensive to utilize. In this work, we introduce a novel method, called "observable propagation" (in short: ObsProp), for finding linear features used by transformer language models in computing a given task -- using almost no data. Our paradigm centers on the concept of observables, linear functionals corresponding to given tasks. We then introduce a mathematical theory for the analysis of feature vectors: we provide theoretical motivation for why LayerNorm nonlinearities do not affect the direction of feature vectors; we also introduce a similarity metric between feature vectors called the coupling coefficient which estimates the degree to which one feature's output correlates with another's. We use ObsProp to perform extensive qualitative investigations into several tasks, including gendered occupational bias, political party prediction, and programming language detection. Our results suggest that ObsProp surpasses traditional approaches for finding feature vectors in the low-data regime, and that ObsProp can be used to better understand the mechanisms responsible for bias in large language models. Code for experiments can be found at github.com/jacobdunefsky/ObservablePropagation.