 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoded Prior Sliced Wasserstein AutoEncoder for learning latent manifold representations
Oct 02, 2020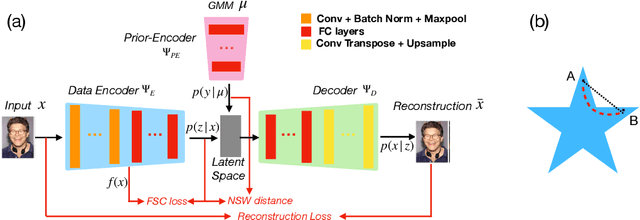
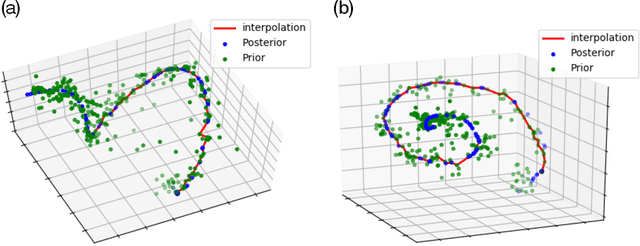


While variational autoencoders have been successful generative models for a variety of tasks, the use of conventional Gaussian or Gaussian mixture priors are limited in their ability to capture topological or geometric properties of data in the latent representation. In this work, we introduce an Encoded Prior Sliced Wasserstein AutoEncoder (EPSWAE) wherein an additional prior-encoder network learns an unconstrained prior to match the encoded data manifold. The autoencoder and prior-encoder networks are iteratively trained using the Sliced Wasserstein Distance (SWD), which efficiently measures the distance between two $\textit{arbitrary}$ sampleable distributions without being constrained to a specific form as in the KL divergence, and without requiring expensive adversarial training. Additionally, we enhance the conventional SWD by introducing a nonlinear shearing, i.e., averaging over random $\textit{nonlinear}$ transformations, to better capture differences between two distributions. The prior is further encouraged to encode the data manifold by use of a structural consistency term that encourages isometry between feature space and latent space. Lastly, interpolation along $\textit{geodesics}$ on the latent space representation of the data manifold generates samples that lie on the manifold and hence is advantageous compared with standard Euclidean interpolation. To this end, we introduce a graph-based algorithm for identifying network-geodesics in latent space from samples of the prior that maximize the density of samples along the path while minimizing total energy. We apply our framework to 3D-spiral, MNIST, and CelebA datasets, and show that its latent representations and interpolations are comparable to the state of the art on equivalent architectures.