 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Signal in the Noise: OOD Detection Through Goodness-of-Fit Testing in Factorised Latent Spaces
May 21, 2026Deep generative models offer a natural foundation for out-of-distribution (OOD) detection, yet prior work has shown that their assigned likelihoods are notoriously unreliable indicators for in- vs out-of-distribution data. In this paper, we address this problem by leveraging the diffeomorphic and mass-preserving properties of continuous normalising flows. Our analysis shows that OOD samples are mapped to noise samples that are highly atypical under the noise prior in ways not captured by the likelihood. Based on this observation, we propose a new method -- Signal in the Noise (SITN) -- for OOD detection on the single-sample level. SITN requires no access to OOD data, incurs minimal computational overhead, and provides strict control of false positive rates. Comprehensive evaluations through standard benchmarks and synthetic perturbations highlight the method's effectiveness and the absence of the complexity bias inherent to likelihood-based methods.
Strategic Classification with Randomised Classifiers
Feb 03, 2025We consider the problem of strategic classification, where a learner must build a model to classify agents based on features that have been strategically modified. Previous work in this area has concentrated on the case when the learner is restricted to deterministic classifiers. In contrast, we perform a theoretical analysis of an extension to this setting that allows the learner to produce a randomised classifier. We show that, under certain conditions, the optimal randomised classifier can achieve better accuracy than the optimal deterministic classifier, but under no conditions can it be worse. When a finite set of training data is available, we show that the excess risk of Strategic Empirical Risk Minimisation over the class of randomised classifiers is bounded in a similar manner as the deterministic case. In both the deterministic and randomised cases, the risk of the classifier produced by the learner converges to that of the corresponding optimal classifier as the volume of available training data grows. Moreover, this convergence happens at the same rate as in the i.i.d. case. Our findings are compared with previous theoretical work analysing the problem of strategic classification. We conclude that randomisation has the potential to alleviate some issues that could be faced in practice without introducing any substantial downsides.
Active Altruism Learning and Information Sufficiency for Autonomous Driving
Oct 09, 2021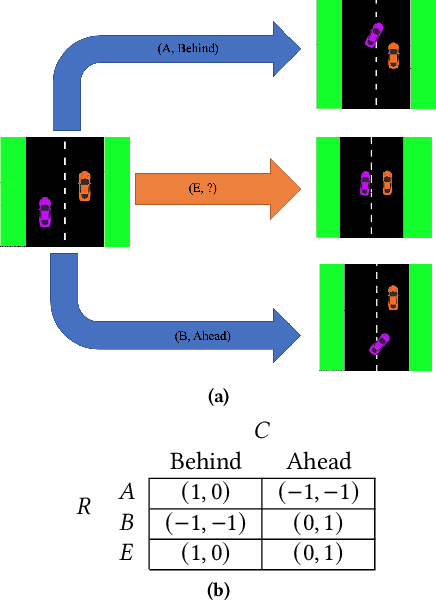
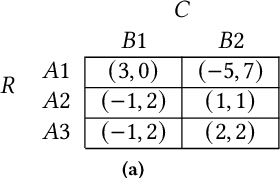
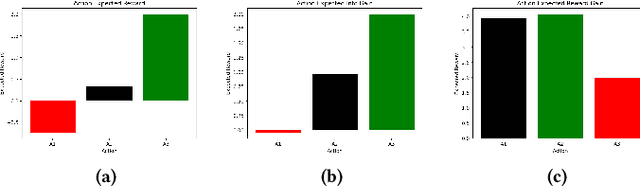
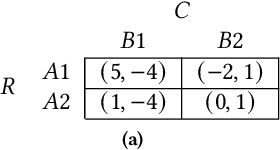
Safe interaction between vehicles requires the ability to choose actions that reveal the preferences of the other vehicles. Since exploratory actions often do not directly contribute to their objective, an interactive vehicle must also able to identify when it is appropriate to perform them. In this work we demonstrate how Active Learning methods can be used to incentivise an autonomous vehicle (AV) to choose actions that reveal information about the altruistic inclinations of another vehicle. We identify a property, Information Sufficiency, that a reward function should have in order to keep exploration from unnecessarily interfering with the pursuit of an objective. We empirically demonstrate that reward functions that do not have Information Sufficiency are prone to inadequate exploration, which can result in sub-optimal behaviour. We propose a reward definition that has Information Sufficiency, and show that it facilitates an AV choosing exploratory actions to estimate altruistic tendency, whilst also compensating for the possibility of conflicting beliefs between vehicles.