 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Time-Scale Convolution for Emotion Recognition from Speech Audio Signals
Mar 06, 2020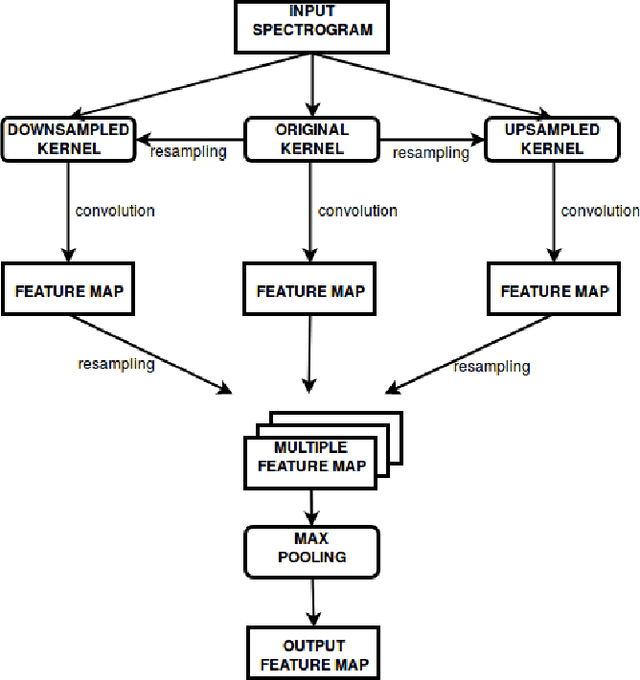
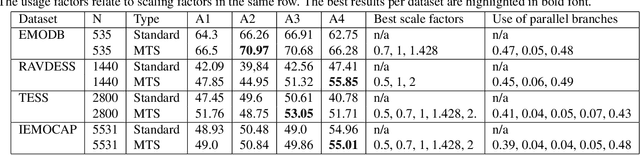
Robustness against temporal variations is important for emotion recognition from speech audio, since emotion is ex-pressed through complex spectral patterns that can exhibit significant local dilation and compression on the time axis depending on speaker and context. To address this and potentially other tasks, we introduce the multi-time-scale (MTS) method to create flexibility towards temporal variations when analyzing time-frequency representations of audio data. MTS extends convolutional neural networks with convolution kernels that are scaled and re-sampled along the time axis, to increase temporal flexibility without increasing the number of trainable parameters compared to standard convolutional layers. We evaluate MTS and standard convolutional layers in different architectures for emotion recognition from speech audio, using 4 datasets of different sizes. The results show that the use of MTS layers consistently improves the generalization of networks of different capacity and depth, compared to standard convolution, especially on smaller datasets