 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCPO: Safe Reinforcement Learning with Safety Critic Policy Optimization
Nov 01, 2023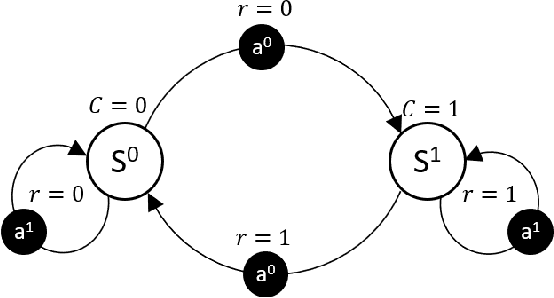
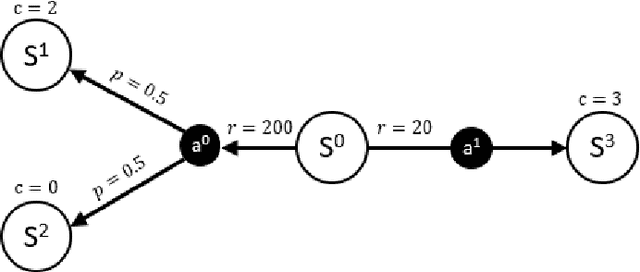
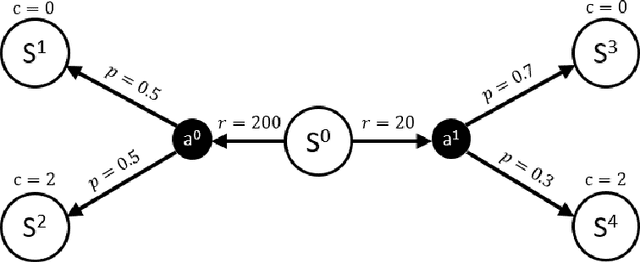
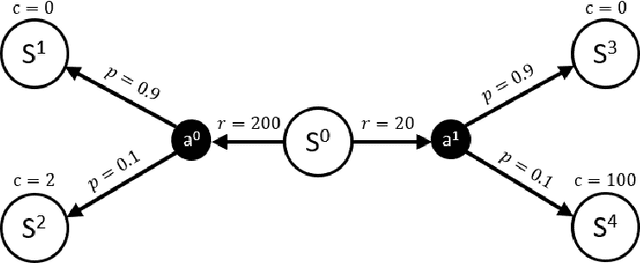
Incorporating safety is an essential prerequisite for broadening the practical applications of reinforcement learning in real-world scenarios. To tackle this challenge, Constrained Markov Decision Processes (CMDPs) are leveraged, which introduce a distinct cost function representing safety violations. In CMDPs' settings, Lagrangian relaxation technique has been employed in previous algorithms to convert constrained optimization problems into unconstrained dual problems. However, these algorithms may inaccurately predict unsafe behavior, resulting in instability while learning the Lagrange multiplier. This study introduces a novel safe reinforcement learning algorithm, Safety Critic Policy Optimization (SCPO). In this study, we define the safety critic, a mechanism that nullifies rewards obtained through violating safety constraints. Furthermore, our theoretical analysis indicates that the proposed algorithm can automatically balance the trade-off between adhering to safety constraints and maximizing rewards. The effectiveness of the SCPO algorithm is empirically validated by benchmarking it against strong baselines.