 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Binary Embedding for GPU-Enabled Exhaustive Retrieval from Billion-Scale Semantic Vectors
Feb 18, 2018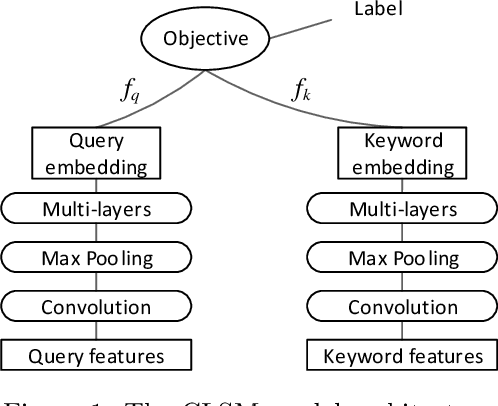
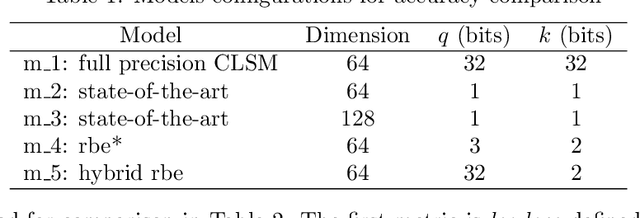
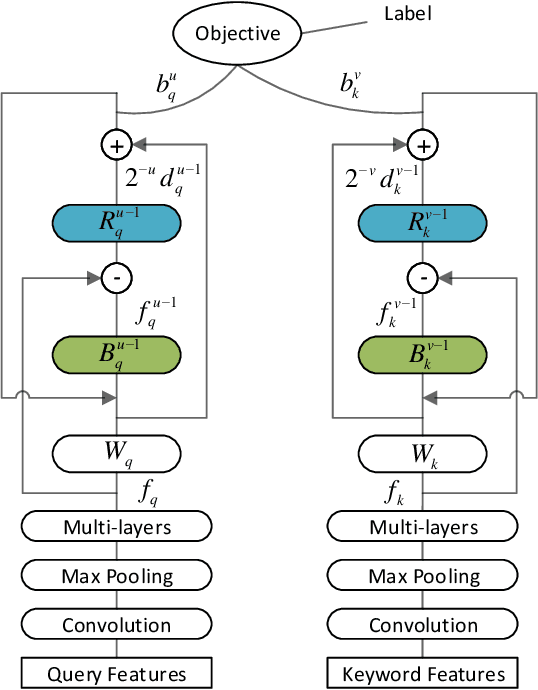

Rapid advances in GPU hardware and multiple areas of Deep Learning open up a new opportunity for billion-scale information retrieval with exhaustive search. Building on top of the powerful concept of semantic learning, this paper proposes a Recurrent Binary Embedding (RBE) model that learns compact representations for real-time retrieval. The model has the unique ability to refine a base binary vector by progressively adding binary residual vectors to meet the desired accuracy. The refined vector enables efficient implementation of exhaustive similarity computation with bit-wise operations, followed by a near- lossless k-NN selection algorithm, also proposed in this paper. The proposed algorithms are integrated into an end-to-end multi-GPU system that retrieves thousands of top items from over a billion candidates in real-time. The RBE model and the retrieval system were evaluated with data from a major paid search engine. When measured against the state-of-the-art model for binary representation and the full precision model for semantic embedding, RBE significantly outperformed the former, and filled in over 80% of the AUC gap in-between. Experiments comparing with our production retrieval system also demonstrated superior performance. While the primary focus of this paper is to build RBE based on a particular class of semantic models, generalizing to other types is straightforward, as exemplified by two different models at the end of the paper.
Deep Embedding Forest: Forest-based Serving with Deep Embedding Features
Mar 15, 2017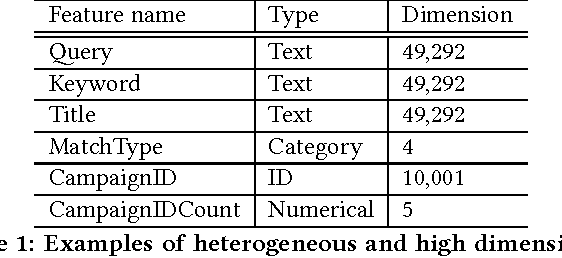
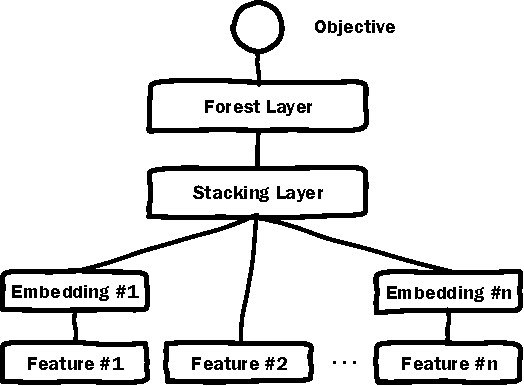
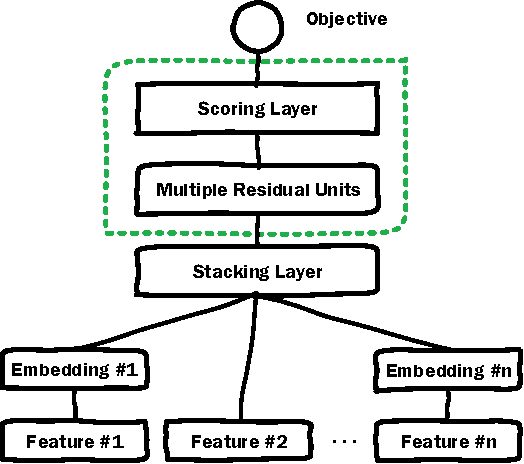

Deep Neural Networks (DNN) have demonstrated superior ability to extract high level embedding vectors from low level features. Despite the success, the serving time is still the bottleneck due to expensive run-time computation of multiple layers of dense matrices. GPGPU, FPGA, or ASIC-based serving systems require additional hardware that are not in the mainstream design of most commercial applications. In contrast, tree or forest-based models are widely adopted because of low serving cost, but heavily depend on carefully engineered features. This work proposes a Deep Embedding Forest model that benefits from the best of both worlds. The model consists of a number of embedding layers and a forest/tree layer. The former maps high dimensional (hundreds of thousands to millions) and heterogeneous low-level features to the lower dimensional (thousands) vectors, and the latter ensures fast serving. Built on top of a representative DNN model called Deep Crossing, and two forest/tree-based models including XGBoost and LightGBM, a two-step Deep Embedding Forest algorithm is demonstrated to achieve on-par or slightly better performance as compared with the DNN counterpart, with only a fraction of serving time on conventional hardware. After comparing with a joint optimization algorithm called partial fuzzification, also proposed in this paper, it is concluded that the two-step Deep Embedding Forest has achieved near optimal performance. Experiments based on large scale data sets (up to 1 billion samples) from a major sponsored search engine proves the efficacy of the proposed model.