 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Adapting Large Language Models to Represent Folktales in Low-Resource Languages
Nov 08, 2024
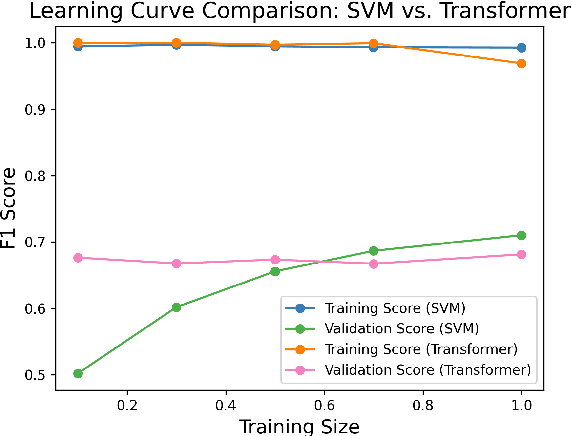


Folktales are a rich resource of knowledge about the society and culture of a civilisation. Digital folklore research aims to use automated techniques to better understand these folktales, and it relies on abstract representations of the textual data. Although a number of large language models (LLMs) claim to be able to represent low-resource langauges such as Irish and Gaelic, we present two classification tasks to explore how useful these representations are, and three adaptations to improve the performance of these models. We find that adapting the models to work with longer sequences, and continuing pre-training on the domain of folktales improves classification performance, although these findings are tempered by the impressive performance of a baseline SVM with non-contextual features.