 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermodynamic Machine Learning through Maximum Work Production
Jun 27, 2020



Adaptive thermodynamic systems -- such as a biological organism attempting to gain survival advantage, an autonomous robot performing a functional task, or a motor protein transporting intracellular nutrients -- can improve their performance by effectively modeling the regularities and stochasticity in their environments. Analogously, but in a purely computational realm, machine learning algorithms seek to estimate models that capture predictable structure and identify irrelevant noise in training data by optimizing performance measures, such as a model's log-likelihood of having generated the data. Is there a sense in which these computational models are physically preferred? For adaptive physical systems we introduce the organizing principle that thermodynamic work is the most relevant performance measure of advantageously modeling an environment. Specifically, a physical agent's model determines how much useful work it can harvest from an environment. We show that when such agents maximize work production they also maximize their environmental model's log-likelihood, establishing an equivalence between thermodynamics and learning. In this way, work maximization appears as an organizing principle that underlies learning in adaptive thermodynamic systems.
Inference, Prediction, and Entropy-Rate Estimation of Continuous-time, Discrete-event Processes
May 07, 2020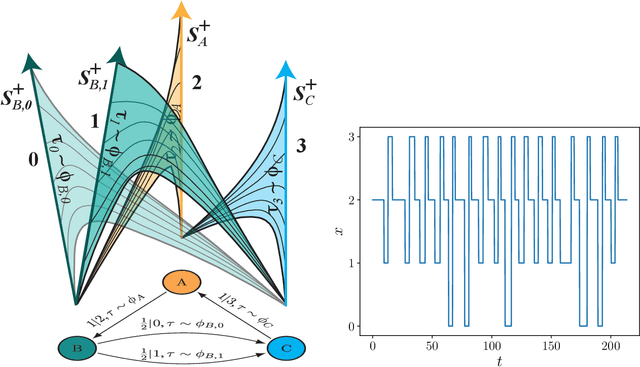
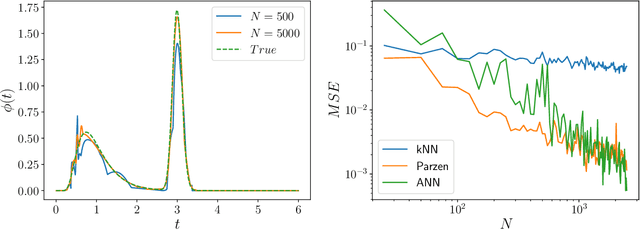
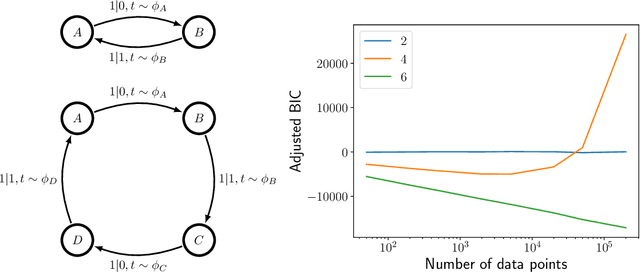
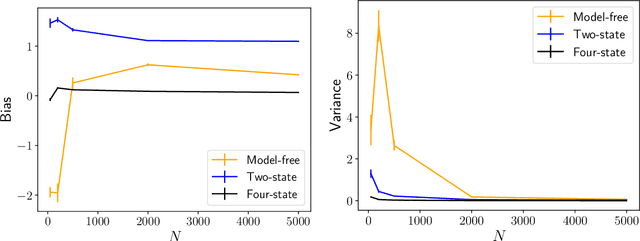
Inferring models, predicting the future, and estimating the entropy rate of discrete-time, discrete-event processes is well-worn ground. However, a much broader class of discrete-event processes operates in continuous-time. Here, we provide new methods for inferring, predicting, and estimating them. The methods rely on an extension of Bayesian structural inference that takes advantage of neural network's universal approximation power. Based on experiments with complex synthetic data, the methods are competitive with the state-of-the-art for prediction and entropy-rate estimation.
Probabilistic Deterministic Finite Automata and Recurrent Networks, Revisited
Oct 17, 2019
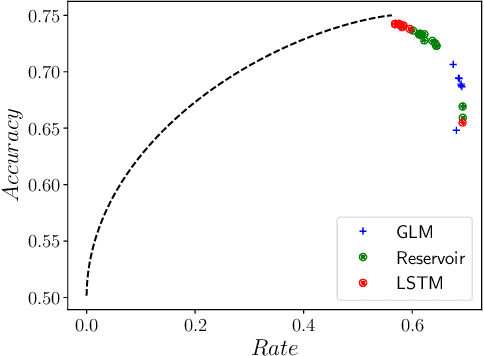


Reservoir computers (RCs) and recurrent neural networks (RNNs) can mimic any finite-state automaton in theory, and some workers demonstrated that this can hold in practice. We test the capability of generalized linear models, RCs, and Long Short-Term Memory (LSTM) RNN architectures to predict the stochastic processes generated by a large suite of probabilistic deterministic finite-state automata (PDFA). PDFAs provide an excellent performance benchmark in that they can be systematically enumerated, the randomness and correlation structure of their generated processes are exactly known, and their optimal memory-limited predictors are easily computed. Unsurprisingly, LSTMs outperform RCs, which outperform generalized linear models. Surprisingly, each of these methods can fall short of the maximal predictive accuracy by as much as 50% after training and, when optimized, tend to fall short of the maximal predictive accuracy by ~5%, even though previously available methods achieve maximal predictive accuracy with orders-of-magnitude less data. Thus, despite the representational universality of RCs and RNNs, using them can engender a surprising predictive gap for simple stimuli. One concludes that there is an important and underappreciated role for methods that infer "causal states" or "predictive state representations".
Classical and Quantum Factors of Channels
Sep 23, 2017


Given a classical channel, a stochastic map from inputs to outputs, can we replace the input with a simple intermediate variable that still yields the correct conditional output distribution? We examine two cases: first, when the intermediate variable is classical; second, when the intermediate variable is quantum. We show that the quantum variable's size is generically smaller than the classical, according to two different measures---cardinality and entropy. We demonstrate optimality conditions for a special case. We end with several related results: a proposal for extending the special case, a demonstration of the impact of quantum phases, and a case study concerning pure versus mixed states.
Pairwise Correlations in Layered Close-Packed Structures
Jul 26, 2014



Given a description of the stacking statistics of layered close-packed structures in the form of a hidden Markov model, we develop analytical expressions for the pairwise correlation functions between the layers. These may be calculated analytically as explicit functions of model parameters or the expressions may be used as a fast, accurate, and efficient way to obtain numerical values. We present several examples, finding agreement with previous work as well as deriving new relations.