 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Pipeline for Machine Learning with Functional Data
Jan 10, 2025Machine learning (ML) models have shown success in applications with an objective of prediction, but the algorithmic complexity of some models makes them difficult to interpret. Methods have been proposed to provide insight into these "black-box" models, but there is little research that focuses on supervised ML when the model inputs are functional data. In this work, we consider two applications from high-consequence spaces with objectives of making predictions using functional data inputs. One application aims to classify material types to identify explosive materials given hyperspectral computed tomography scans of the materials. The other application considers the forensics science task of connecting an inkjet printed document to the source printer using color signatures extracted by Raman spectroscopy. An instinctive route to consider for analyzing these data is a data driven ML model for classification, but due to the high consequence nature of the applications, we argue it is important to appropriately account for the nature of the data in the analysis to not obscure or misrepresent patterns. As such, we propose the Variable importance Explainable Elastic Shape Analysis (VEESA) pipeline for training ML models with functional data that (1) accounts for the vertical and horizontal variability in the functional data and (2) provides an explanation in the original data space of how the model uses variability in the functional data for prediction. The pipeline makes use of elastic functional principal components analysis (efPCA) to generate uncorrelated model inputs and permutation feature importance (PFI) to identify the principal components important for prediction. The variability captured by the important principal components in visualized the original data space. We ultimately discuss ideas for natural extensions of the VEESA pipeline and challenges for future research.
Dimensionality Reduction using Elastic Measures
Sep 07, 2022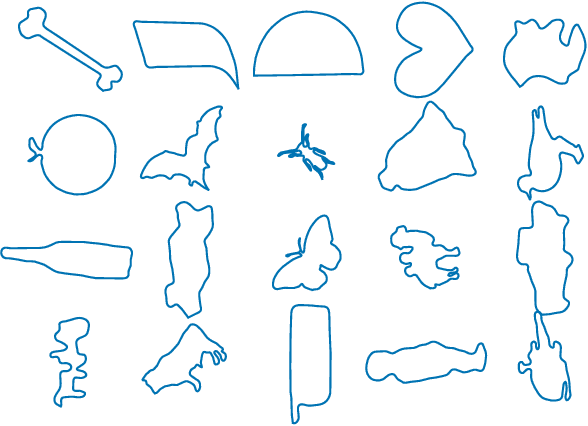
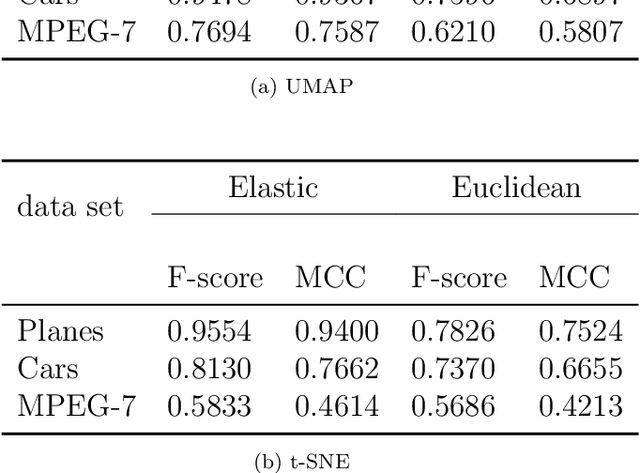
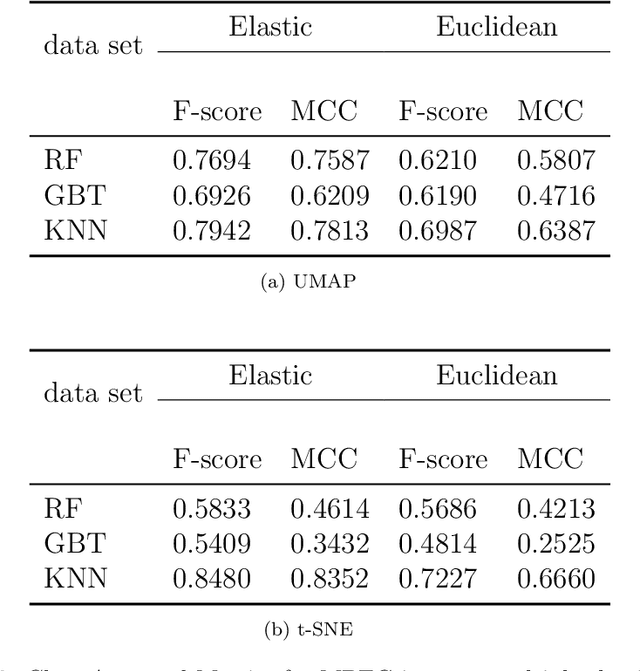
With the recent surge in big data analytics for hyper-dimensional data there is a renewed interest in dimensionality reduction techniques for machine learning applications. In order for these methods to improve performance gains and understanding of the underlying data, a proper metric needs to be identified. This step is often overlooked and metrics are typically chosen without consideration of the underlying geometry of the data. In this paper, we present a method for incorporating elastic metrics into the t-distributed Stochastic Neighbor Embedding (t-SNE) and Uniform Manifold Approximation and Projection (UMAP). We apply our method to functional data, which is uniquely characterized by rotations, parameterization, and scale. If these properties are ignored, they can lead to incorrect analysis and poor classification performance. Through our method we demonstrate improved performance on shape identification tasks for three benchmark data sets (MPEG-7, Car data set, and Plane data set of Thankoor), where we achieve 0.77, 0.95, and 1.00 F1 score, respectively.
Spatio-temporal extreme event modeling of terror insurgencies
Oct 29, 2021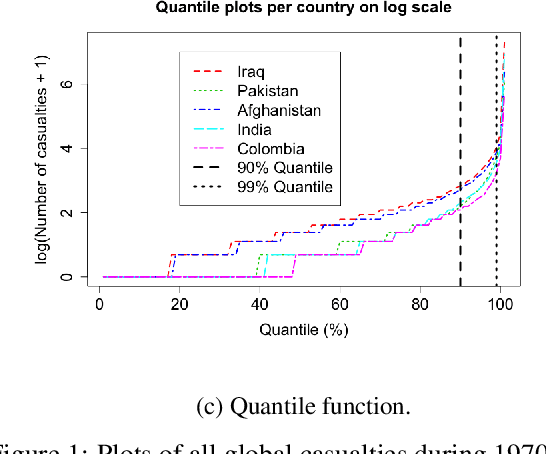
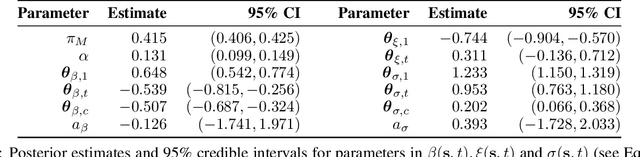
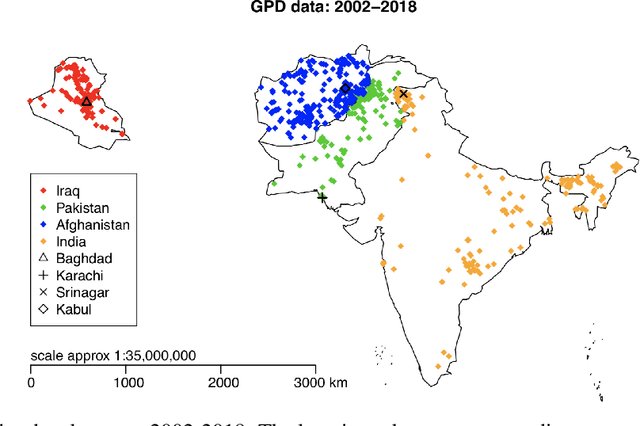
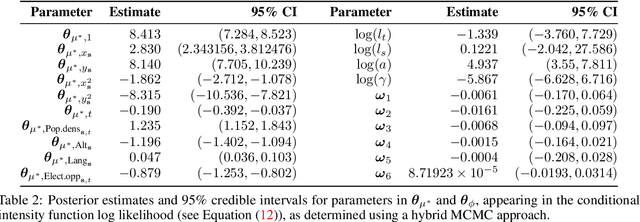
Extreme events with potential deadly outcomes, such as those organized by terror groups, are highly unpredictable in nature and an imminent threat to society. In particular, quantifying the likelihood of a terror attack occurring in an arbitrary space-time region and its relative societal risk, would facilitate informed measures that would strengthen national security. This paper introduces a novel self-exciting marked spatio-temporal model for attacks whose inhomogeneous baseline intensity is written as a function of covariates. Its triggering intensity is succinctly modeled with a Gaussian Process prior distribution to flexibly capture intricate spatio-temporal dependencies between an arbitrary attack and previous terror events. By inferring the parameters of this model, we highlight specific space-time areas in which attacks are likely to occur. Furthermore, by measuring the outcome of an attack in terms of the number of casualties it produces, we introduce a novel mixture distribution for the number of casualties. This distribution flexibly handles low and high number of casualties and the discrete nature of the data through a {\it Generalized ZipF} distribution. We rely on a customized Markov chain Monte Carlo (MCMC) method to estimate the model parameters. We illustrate the methodology with data from the open source Global Terrorism Database (GTD) that correspond to attacks in Afghanistan from 2013-2018. We show that our model is able to predict the intensity of future attacks for 2019-2021 while considering various covariates of interest such as population density, number of regional languages spoken, and the density of population supporting the opposing government.