Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Building Interpretable Rule-Based Data-to-Text Systems
Feb 28, 2025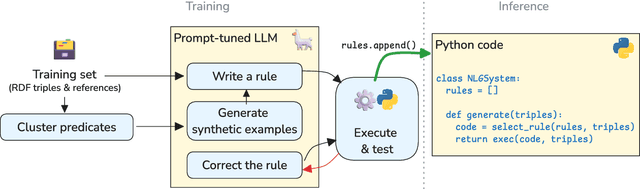


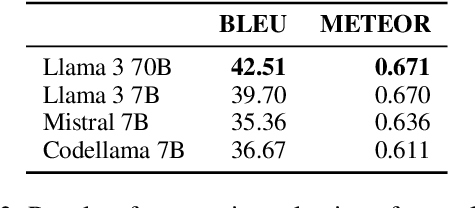
We introduce a simple approach that uses a large language model (LLM) to automatically implement a fully interpretable rule-based data-to-text system in pure Python. Experimental evaluation on the WebNLG dataset showed that such a constructed system produces text of better quality (according to the BLEU and BLEURT metrics) than the same LLM prompted to directly produce outputs, and produces fewer hallucinations than a BART language model fine-tuned on the same data. Furthermore, at runtime, the approach generates text in a fraction of the processing time required by neural approaches, using only a single CPU
Via