 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepwise functional refoundation of relational concept analysis
Oct 10, 2023Relational concept analysis (RCA) is an extension of formal concept analysis allowing to deal with several related contexts simultaneously. It has been designed for learning description logic theories from data and used within various applications. A puzzling observation about RCA is that it returns a single family of concept lattices although, when the data feature circular dependencies, other solutions may be considered acceptable. The semantics of RCA, provided in an operational way, does not shed light on this issue. In this report, we define these acceptable solutions as those families of concept lattices which belong to the space determined by the initial contexts (well-formed), cannot scale new attributes (saturated), and refer only to concepts of the family (self-supported). We adopt a functional view on the RCA process by defining the space of well-formed solutions and two functions on that space: one expansive and the other contractive. We show that the acceptable solutions are the common fixed points of both functions. This is achieved step-by-step by starting from a minimal version of RCA that considers only one single context defined on a space of contexts and a space of lattices. These spaces are then joined into a single space of context-lattice pairs, which is further extended to a space of indexed families of context-lattice pairs representing the objects manip
The category of networks of ontologies
Dec 10, 2014
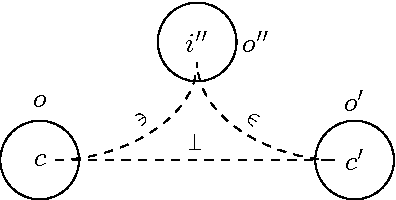

The semantic web has led to the deployment of ontologies on the web connected through various relations and, in particular, alignments of their vocabularies. There exists several semantics for alignments which make difficult interoperation between different interpretation of networks of ontologies. Here we present an abstraction of these semantics which allows for defining the notions of closure and consistency for networks of ontologies independently from the precise semantics. We also show that networks of ontologies with specific notions of morphisms define categories of networks of ontologies.
Evolving knowledge through negotiation
Jul 26, 2012


Semantic web information is at the extremities of long pipelines held by human beings. They are at the origin of information and they will consume it either explicitly because the information will be delivered to them in a readable way, or implicitly because the computer processes consuming this information will affect them. Computers are particularly capable of dealing with information the way it is provided to them. However, people may assign to the information they provide a narrower meaning than semantic technologies may consider. This is typically what happens when people do not think their assertions as ambiguous. Model theory, used to provide semantics to the information on the semantic web, is particularly apt at preserving ambiguity and delivering it to the other side of the pipeline. Indeed, it preserves as much interpretations as possible. This quality for reasoning efficiency, becomes a deficiency for accurate communication and meaning preservation. Overcoming it may require either interactive feedback or preservation of the source context. Work from social science and humanities may help solving this particular problem.
MeLinDa: an interlinking framework for the web of data
Jul 22, 2011
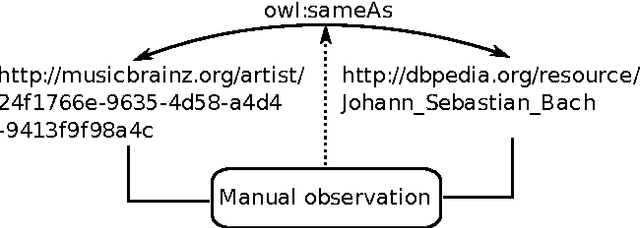

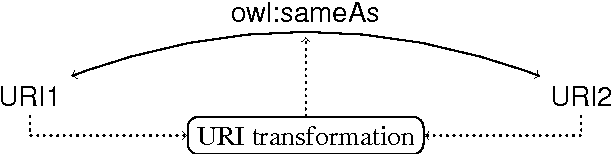
The web of data consists of data published on the web in such a way that they can be interpreted and connected together. It is thus critical to establish links between these data, both for the web of data and for the semantic web that it contributes to feed. We consider here the various techniques developed for that purpose and analyze their commonalities and differences. We propose a general framework and show how the diverse techniques fit in the framework. From this framework we consider the relation between data interlinking and ontology matching. Although, they can be considered similar at a certain level (they both relate formal entities), they serve different purposes, but would find a mutual benefit at collaborating. We thus present a scheme under which it is possible for data linking tools to take advantage of ontology alignments.