 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNiaAutoARM: Automated generation and evaluation of Association Rule Mining pipelines
Dec 30, 2024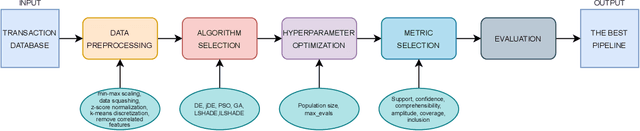

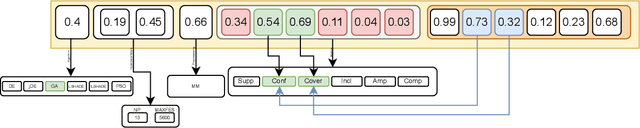
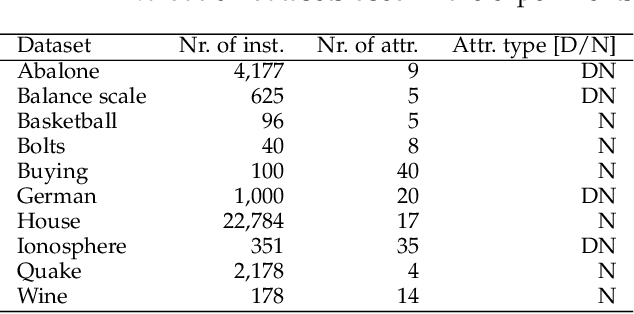
The Numerical Association Rule Mining paradigm that includes concurrent dealing with numerical and categorical attributes is beneficial for discovering associations from datasets consisting of both features. The process is not considered as easy since it incorporates several processing steps running sequentially that form an entire pipeline, e.g., preprocessing, algorithm selection, hyper-parameter optimization, and the definition of metrics evaluating the quality of the association rule. In this paper, we proposed a novel Automated Machine Learning method, NiaAutoARM, for constructing the full association rule mining pipelines based on stochastic population-based meta-heuristics automatically. Along with the theoretical representation of the proposed method, we also present a comprehensive experimental evaluation of the proposed method.
A comprehensive review of visualization methods for association rule mining: Taxonomy, Challenges, Open problems and Future ideas
Feb 24, 2023Association rule mining is intended for searching for the relationships between attributes in transaction databases. The whole process of rule discovery is very complex, and involves pre-processing techniques, a rule mining step, and post-processing, in which visualization is carried out. Visualization of discovered association rules is an essential step within the whole association rule mining pipeline, to enhance the understanding of users on the results of rule mining. Several association rule mining and visualization methods have been developed during the past decades. This review paper aims to create a literature review, identify the main techniques published in peer-reviewed literature, examine each method's main features, and present the main applications in the field. Defining the future steps of this research area is another goal of this review paper.
Time series numerical association rule mining variants in smart agriculture
Dec 07, 2022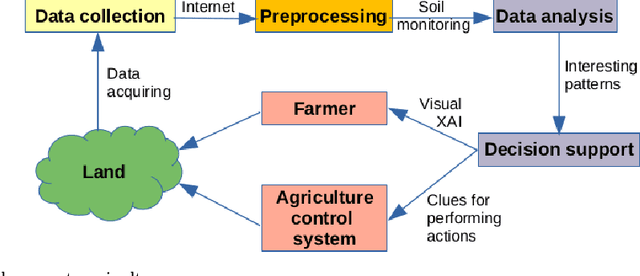



Numerical association rule mining offers a very efficient way of mining association rules, where algorithms can operate directly with categorical and numerical attributes. These methods are suitable for mining different transaction databases, where data are entered sequentially. However, little attention has been paid to the time series numerical association rule mining, which offers a new technique for extracting association rules from time series data. This paper presents a new algorithmic method for time series numerical association rule mining and its application in smart agriculture. We offer a concept of a hardware environment for monitoring plant parameters and a novel data mining method with practical experiments. The practical experiments showed the method's potential and opened the door for further extension.
A brief overview of swarm intelligence-based algorithms for numerical association rule mining
Oct 29, 2020


Numerical Association Rule Mining is a popular variant of Association Rule Mining, where numerical attributes are handled without discretization. This means that the algorithms for dealing with this problem can operate directly, not only with categorical, but also with numerical attributes. Until recently, a big portion of these algorithms were based on a stochastic nature-inspired population-based paradigm. As a result, evolutionary and swarm intelligence-based algorithms showed big efficiency for dealing with the problem. In line with this, the main mission of this chapter is to make a historical overview of swarm intelligence-based algorithms for Numerical Association Rule Mining, as well as to present the main features of these algorithms for the observed problem. A taxonomy of the algorithms was proposed on the basis of the applied features found in this overview. Challenges, waiting in the future, finish this paper.
uARMSolver: A framework for Association Rule Mining
Oct 21, 2020


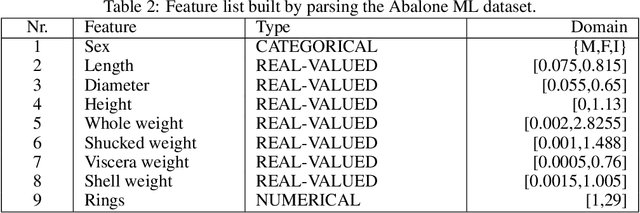
The paper presents a novel software framework for Association Rule Mining named uARMSolver. The framework is written fully in C++ and runs on all platforms. It allows users to preprocess their data in a transaction database, to make discretization of data, to search for association rules and to guide a presentation/visualization of the best rules found using external tools. As opposed to the existing software packages or frameworks, this also supports numerical and real-valued types of attributes besides the categorical ones. Mining the association rules is defined as an optimization and solved using the nature-inspired algorithms that can be incorporated easily. Because the algorithms normally discover a huge amount of association rules, the framework enables a modular inclusion of so-called visual guiders for extracting the knowledge hidden in data, and visualize these using external tools.
Association rules over time
Oct 08, 2020

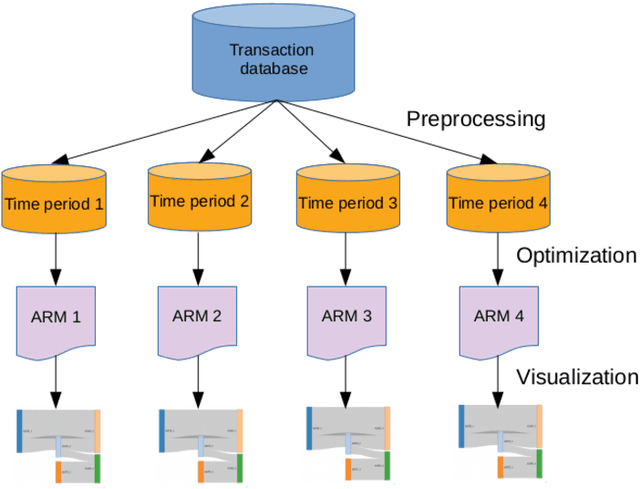
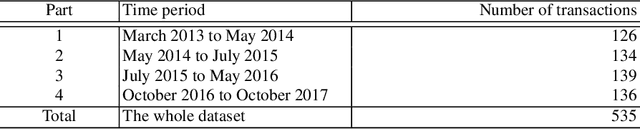
Decisions made nowadays by Artificial Intelligence powered systems are usually hard for users to understand. One of the more important issues faced by developers is exposed as how to create more explainable Machine Learning models. In line with this, more explainable techniques need to be developed, where visual explanation also plays a more important role. This technique could also be applied successfully for explaining the results of Association Rule Mining.This Chapter focuses on two issues: (1) How to discover the relevant association rules, and (2) How to express relations between more attributes visually. For the solution of the first issue, the proposed method uses Differential Evolution, while Sankey diagrams are adopted to solve the second one. This method was applied to a transaction database containing data generated by an amateur cyclist in past seasons, using a mobile device worn during the realization of training sessions that is divided into four time periods. The results of visualization showed that a trend in improving performance of an athlete can be indicated by changing the attributes appearing in the selected association rules in different time periods.
Discovering associations in COVID-19 related research papers
Apr 06, 2020

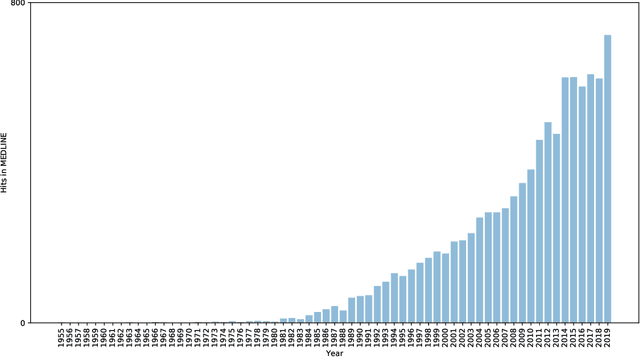

A COVID-19 pandemic has already proven itself to be a global challenge. It proves how vulnerable humanity can be. It has also mobilized researchers from different sciences and different countries in the search for a way to fight this potentially fatal disease. In line with this, our study analyses the abstracts of papers related to COVID-19 and coronavirus-related-research using association rule text mining in order to find the most interestingness words, on the one hand, and relationships between them on the other. Then, a method, called information cartography, was applied for extracting structured knowledge from a huge amount of association rules. On the basis of these methods, the purpose of our study was to show how researchers have responded in similar epidemic/pandemic situations throughout history.
Information cartography in association rule mining
Feb 29, 2020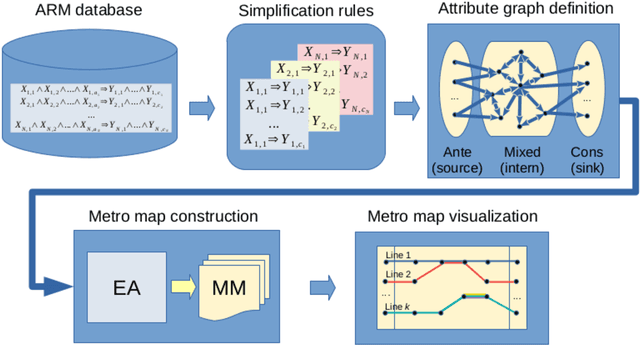
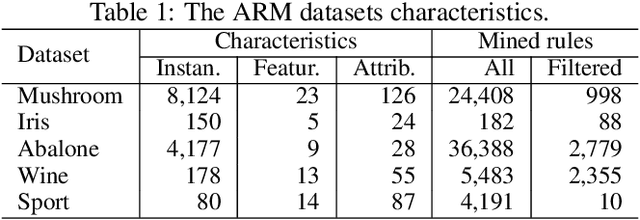
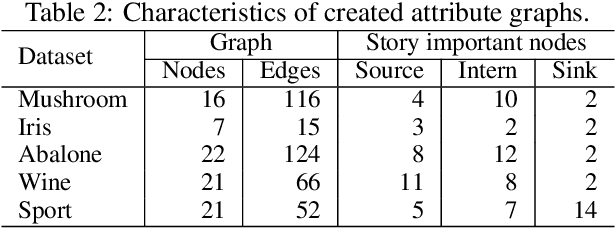

Association Rule Mining is a data mining method for discovering the interesting relations between attributes in a huge transaction database. Typically, algorithms for association rule mining generate a huge number of association rules, from which it is hard to extract structured knowledge and automatically present this in a form that would be suitable for the user. Recently, an information cartography has been proposed for creating structured summaries of information and visualizing with methodology called "metro maps". This was applied to many problem domains. In the hope of widening its applicability domain, the aim of this study is to develop a method for the automatic creation of metro maps of information obtained by association rule mining. Although the proposed method consists of multiple steps, its core presents metro map construction that is defined in the study as an optimization problem, which is solved using an evolutionary algorithm. Finally, this was applied to four well-known UCI Machine Learning datasets and one sport dataset. Visualizing the resulted metro maps not only justifies the fact this is a suitable tool for presenting structured knowledge hidden in data, but also that they can even tell stories to users.
Population-based metaheuristics for Association Rule Text Mining
Jan 17, 2020
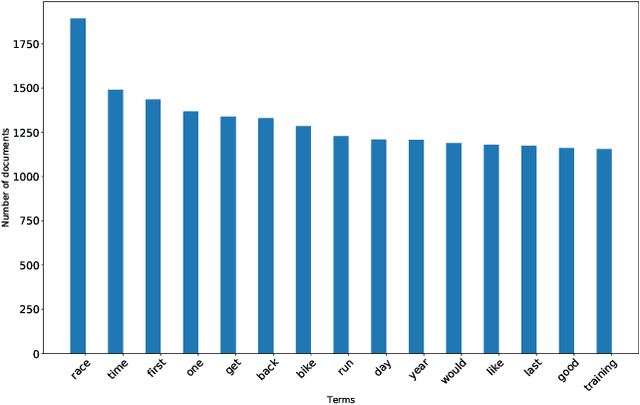
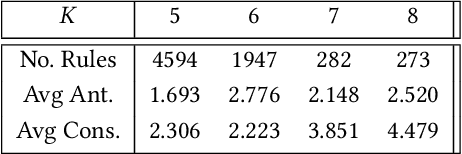
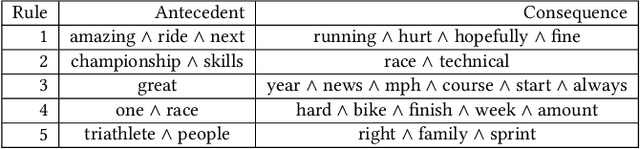
Nowadays, the majority of data on the Internet is held in an unstructured format, like websites and e-mails. The importance of analyzing these data has been growing day by day. Similar to data mining on structured data, text mining methods for handling unstructured data have also received increasing attention from the research community. The paper deals with the problem of Association Rule Text Mining. To solve the problem, the PSO-ARTM method was proposed, that consists of three steps: Text preprocessing, Association Rule Text Mining using population-based metaheuristics, and text postprocessing. The method was applied to a transaction database obtained from professional triathlon athletes' blogs and news posted on their websites. The obtained results reveal that the proposed method is suitable for Association Rule Text Mining and, therefore, offers a promising way for further development.
Modeling preference time in middle distance triathlons
Jul 03, 2017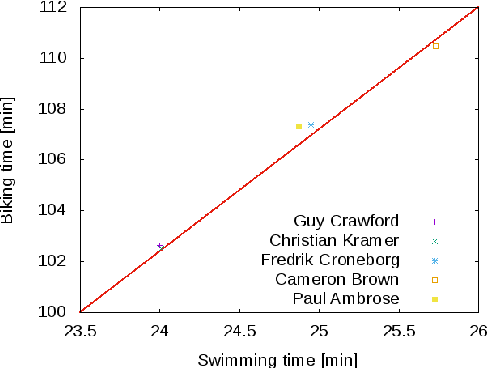
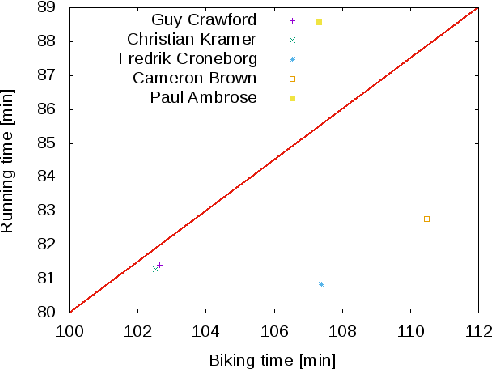
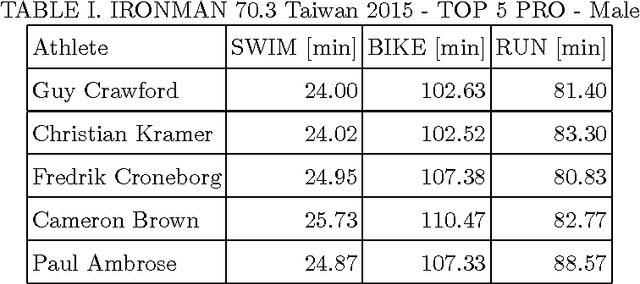

Modeling preference time in triathlons means predicting the intermediate times of particular sports disciplines by a given overall finish time in a specific triathlon course for the athlete with the known personal best result. This is a hard task for athletes and sport trainers due to a lot of different factors that need to be taken into account, e.g., athlete's abilities, health, mental preparations and even their current sports form. So far, this process was calculated manually without any specific software tools or using the artificial intelligence. This paper presents the new solution for modeling preference time in middle distance triathlons based on particle swarm optimization algorithm and archive of existing sports results. Initial results are presented, which suggest the usefulness of proposed approach, while remarks for future improvements and use are also emphasized.