 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFragility, Robustness and Antifragility in Deep Learning
Dec 23, 2023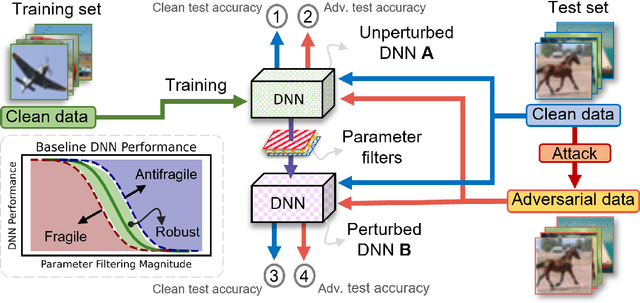
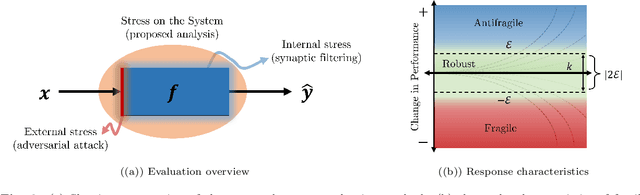
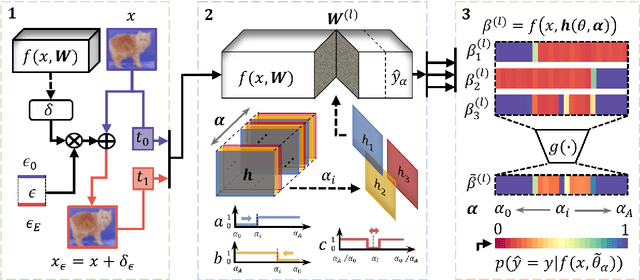
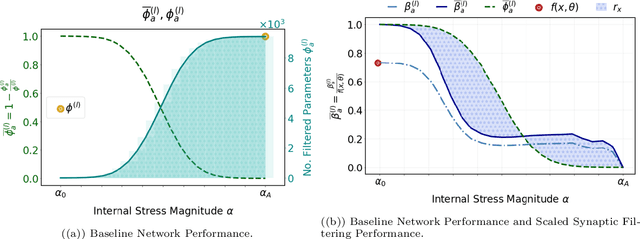
We propose a systematic analysis of deep neural networks (DNNs) based on a signal processing technique for network parameter removal, in the form of synaptic filters that identifies the fragility, robustness and antifragility characteristics of DNN parameters. Our proposed analysis investigates if the DNN performance is impacted negatively, invariantly, or positively on both clean and adversarially perturbed test datasets when the DNN undergoes synaptic filtering. We define three \textit{filtering scores} for quantifying the fragility, robustness and antifragility characteristics of DNN parameters based on the performances for (i) clean dataset, (ii) adversarial dataset, and (iii) the difference in performances of clean and adversarial datasets. We validate the proposed systematic analysis on ResNet-18, ResNet-50, SqueezeNet-v1.1 and ShuffleNet V2 x1.0 network architectures for MNIST, CIFAR10 and Tiny ImageNet datasets. The filtering scores, for a given network architecture, identify network parameters that are invariant in characteristics across different datasets over learning epochs. Vice-versa, for a given dataset, the filtering scores identify the parameters that are invariant in characteristics across different network architectures. We show that our synaptic filtering method improves the test accuracy of ResNet and ShuffleNet models on adversarial datasets when only the robust and antifragile parameters are selectively retrained at any given epoch, thus demonstrating applications of the proposed strategy in improving model robustness.
Adversarial Robustness in Deep Learning: Attacks on Fragile Neurons
Jan 31, 2022We identify fragile and robust neurons of deep learning architectures using nodal dropouts of the first convolutional layer. Using an adversarial targeting algorithm, we correlate these neurons with the distribution of adversarial attacks on the network. Adversarial robustness of neural networks has gained significant attention in recent times and highlights intrinsic weaknesses of deep learning networks against carefully constructed distortion applied to input images. In this paper, we evaluate the robustness of state-of-the-art image classification models trained on the MNIST and CIFAR10 datasets against the fast gradient sign method attack, a simple yet effective method of deceiving neural networks. Our method identifies the specific neurons of a network that are most affected by the adversarial attack being applied. We, therefore, propose to make fragile neurons more robust against these attacks by compressing features within robust neurons and amplifying the fragile neurons proportionally.