 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation
May 06, 2026We present our winning system for Task~B (generation with reference passages) in SemEval-2026 Task~8: MTRAGEval. Our method is a heterogeneous ensemble of seven LLMs with two prompting variants, where a GPT-4o-mini judge selects the best candidate per instance. We ranked 1st out of 26 teams, achieving a conditioned harmonic mean of 0.7827 and outperforming the strongest baseline (gpt-oss-120b, 0.6390). Ablations show that diversity in model families, scales, and prompting strategies is essential, with the ensemble consistently beating any single model. We also introduce Meno-Lite-0.1, a 7B domain-adapted model with a strong cost--performance trade-off, and analyse MTRAGEval, highlighting annotation limitations and directions for improvement. Our code is publicly available: https://github.com/RaguTeam/ragu_mtrag_semeval
TAM-Eval: Evaluating LLMs for Automated Unit Test Maintenance
Jan 26, 2026While Large Language Models (LLMs) have shown promise in software engineering, their application to unit testing remains largely confined to isolated test generation or oracle prediction, neglecting the broader challenge of test suite maintenance. We introduce TAM-Eval (Test Automated Maintenance Evaluation), a framework and benchmark designed to evaluate model performance across three core test maintenance scenarios: creation, repair, and updating of test suites. Unlike prior work limited to function-level tasks, TAM-Eval operates at the test file level, while maintaining access to full repository context during isolated evaluation, better reflecting real-world maintenance workflows. Our benchmark comprises 1,539 automatically extracted and validated scenarios from Python, Java, and Go projects. TAM-Eval supports system-agnostic evaluation of both raw LLMs and agentic workflows, using a reference-free protocol based on test suite pass rate, code coverage, and mutation testing. Empirical results indicate that state-of-the-art LLMs have limited capabilities in realistic test maintenance processes and yield only marginal improvements in test effectiveness. We release TAM-Eval as an open-source framework to support future research in automated software testing. Our data and code are publicly available at https://github.com/trndcenter/TAM-Eval.
Pisets: A Robust Speech Recognition System for Lectures and Interviews
Jan 26, 2026This work presents a speech-to-text system "Pisets" for scientists and journalists which is based on a three-component architecture aimed at improving speech recognition accuracy while minimizing errors and hallucinations associated with the Whisper model. The architecture comprises primary recognition using Wav2Vec2, false positive filtering via the Audio Spectrogram Transformer (AST), and final speech recognition through Whisper. The implementation of curriculum learning methods and the utilization of diverse Russian-language speech corpora significantly enhanced the system's effectiveness. Additionally, advanced uncertainty modeling techniques were introduced, contributing to further improvements in transcription quality. The proposed approaches ensure robust transcribing of long audio data across various acoustic conditions compared to WhisperX and the usual Whisper model. The source code of "Pisets" system is publicly available at GitHub: https://github.com/bond005/pisets.
RM -RF: Reward Model for Run-Free Unit Test Evaluation
Jan 19, 2026We present RM-RF, a lightweight reward model for run-free evaluation of automatically generated unit tests. Instead of repeatedly compiling and executing candidate tests, RM-RF predicts - from source and test code alone - three execution-derived signals: (1) whether the augmented test suite compiles and runs successfully, (2) whether the generated test cases increase code coverage, and (3) whether the generated test cases improve the mutation kill rate. To train and evaluate RM-RF we assemble a multilingual dataset (Java, Python, Go) of focal files, test files, and candidate test additions labeled by an execution-based pipeline, and we release an associated dataset and methodology for comparative evaluation. We tested multiple model families and tuning regimes (zero-shot, full fine-tuning, and PEFT via LoRA), achieving an average F1 of 0.69 across the three targets. Compared to conventional compile-and-run instruments, RM-RF provides substantially lower latency and infrastructure cost while delivering competitive predictive fidelity, enabling fast, scalable feedback for large-scale test generation and RL-based code optimization.
Algorithms For Automatic Accentuation And Transcription Of Russian Texts In Speech Recognition Systems
Oct 03, 2024This paper presents an overview of rule-based system for automatic accentuation and phonemic transcription of Russian texts for speech connected tasks, such as Automatic Speech Recognition (ASR). Two parts of the developed system, accentuation and transcription, use different approaches to achieve correct phonemic representations of input phrases. Accentuation is based on "Grammatical dictionary of the Russian language" of A.A. Zaliznyak and wiktionary corpus. To distinguish homographs, the accentuation system also utilises morphological information of the sentences based on Recurrent Neural Networks (RNN). Transcription algorithms apply the rules presented in the monograph of B.M. Lobanov and L.I. Tsirulnik "Computer Synthesis and Voice Cloning". The rules described in the present paper are implemented in an open-source module, which can be of use to any scientific study connected to ASR or Speech To Text (STT) tasks. Automatically marked up text annotations of the Russian Voxforge database were used as training data for an acoustic model in CMU Sphinx. The resulting acoustic model was evaluated on cross-validation, mean Word Accuracy being 71.2%. The developed toolkit is written in the Python language and is accessible on GitHub for any researcher interested.
More layers! End-to-end regression and uncertainty on tabular data with deep learning
Dec 07, 2021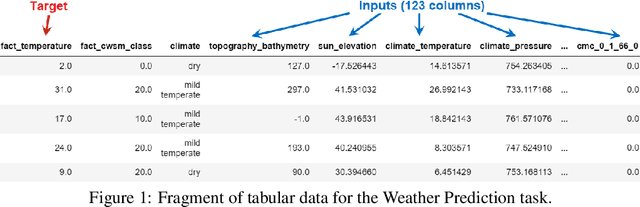
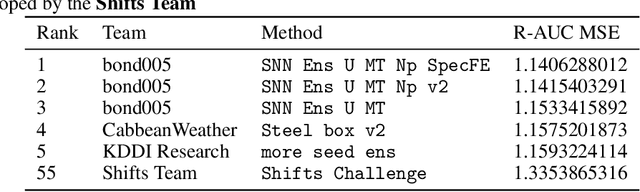
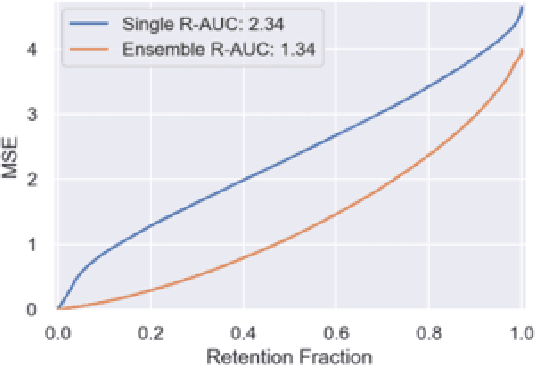
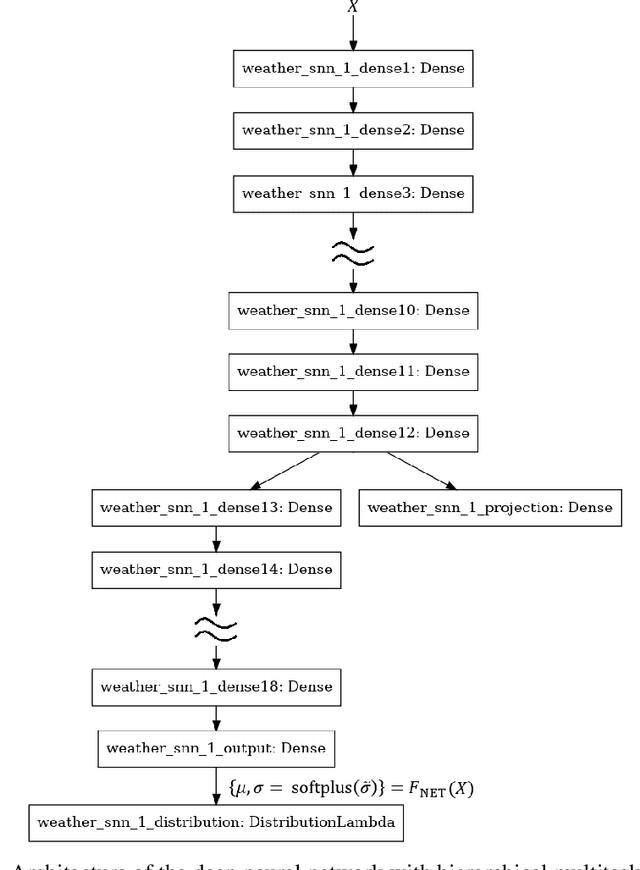
This paper attempts to analyze the effectiveness of deep learning for tabular data processing. It is believed that decision trees and their ensembles is the leading method in this domain, and deep neural networks must be content with computer vision and so on. But the deep neural network is a framework for building gradient-based hierarchical representations, and this key feature should be able to provide the best processing of generic structured (tabular) data, not just image matrices and audio spectrograms. This problem is considered through the prism of the Weather Prediction track in the Yandex Shifts challenge (in other words, the Yandex Shifts Weather task). This task is a variant of the classical tabular data regression problem. It is also connected with another important problem: generalization and uncertainty in machine learning. This paper proposes an end-to-end algorithm for solving the problem of regression with uncertainty on tabular data, which is based on the combination of four ideas: 1) deep ensemble of self-normalizing neural networks, 2) regression as parameter estimation of the Gaussian target error distribution, 3) hierarchical multitask learning, and 4) simple data preprocessing. Three modifications of the proposed algorithm form the top-3 leaderboard of the Yandex Shifts Weather challenge respectively. This paper considers that this success has occurred due to the fundamental properties of the deep learning algorithm, and tries to prove this.