 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovScore: Evaluation of Multi-Document Abstractive Title Set Generation
Jul 24, 2024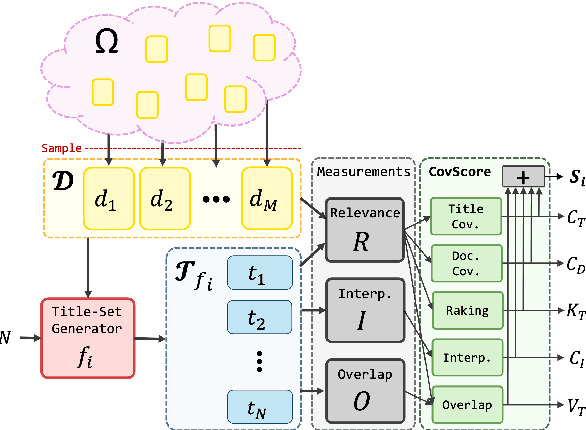
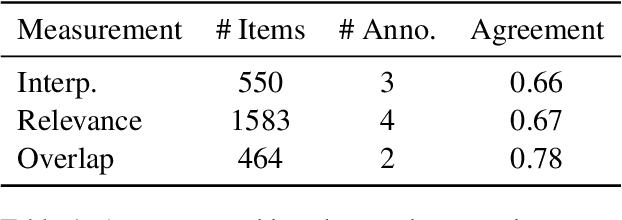
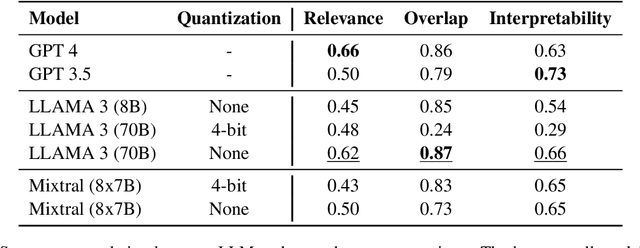
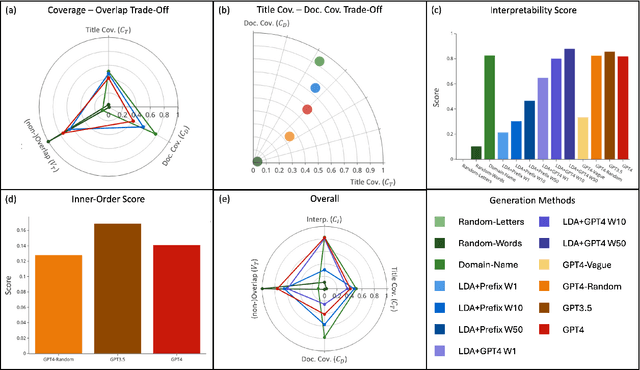
This paper introduces CovScore, an automatic reference-less methodology for evaluating thematic title sets, extracted from a corpus of documents. While such extraction methods are widely used, evaluating their effectiveness remains an open question. Moreover, some existing practices heavily rely on slow and laborious human annotation procedures. Inspired by recently introduced LLM-based judge methods, we propose a novel methodology that decomposes quality into five main metrics along different aspects of evaluation. This framing simplifies and expedites the manual evaluation process and enables automatic and independent LLM-based evaluation. As a test case, we apply our approach to a corpus of Holocaust survivor testimonies, motivated both by its relevance to title set extraction and by the moral significance of this pursuit. We validate the methodology by experimenting with naturalistic and synthetic title set generation systems and compare their performance with the methodology.