 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReparameterization trick for discrete variables
Nov 04, 2016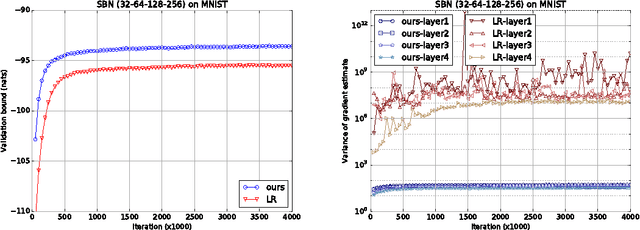

Low-variance gradient estimation is crucial for learning directed graphical models parameterized by neural networks, where the reparameterization trick is widely used for those with continuous variables. While this technique gives low-variance gradient estimates, it has not been directly applicable to discrete variables, the sampling of which inherently requires discontinuous operations. We argue that the discontinuity can be bypassed by marginalizing out the variable of interest, which results in a new reparameterization trick for discrete variables. This reparameterization greatly reduces the variance, which is understood by regarding the method as an application of common random numbers to the estimation. The resulting estimator is theoretically guaranteed to have a variance not larger than that of the likelihood-ratio method with the optimal input-dependent baseline. We give empirical results for variational learning of sigmoid belief networks.