 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical-Questions-of-Thought: Steering LLM reasoning with Argumentative Querying
Dec 19, 2024Studies have underscored how, regardless of the recent breakthrough and swift advances in AI research, even state-of-the-art Large Language models (LLMs) continue to struggle when performing logical and mathematical reasoning. The results seem to suggest that LLMs still work as (highly advanced) data pattern identifiers, scoring poorly when attempting to generalise and solve reasoning problems the models have never previously seen or that are not close to samples presented in their training data. To address this compelling concern, this paper makes use of the notion of critical questions from the literature on argumentation theory, focusing in particular on Toulmin's model of argumentation. We show that employing these critical questions can improve the reasoning capabilities of LLMs. By probing the rationale behind the models' reasoning process, the LLM can assess whether some logical mistake is occurring and correct it before providing the final reply to the user prompt. The underlying idea is drawn from the gold standard of any valid argumentative procedure: the conclusion is valid if it is entailed by accepted premises. Or, to paraphrase such Aristotelian principle in a real-world approximation, characterised by incomplete information and presumptive logic, the conclusion is valid if not proved otherwise. This approach successfully steers the models' output through a reasoning pipeline, resulting in better performance against the baseline and its Chain-of-Thought (CoT) implementation. To this end, an extensive evaluation of the proposed approach on the MT-Bench Reasoning and Math tasks across a range of LLMs is provided.
Can formal argumentative reasoning enhance LLMs performances?
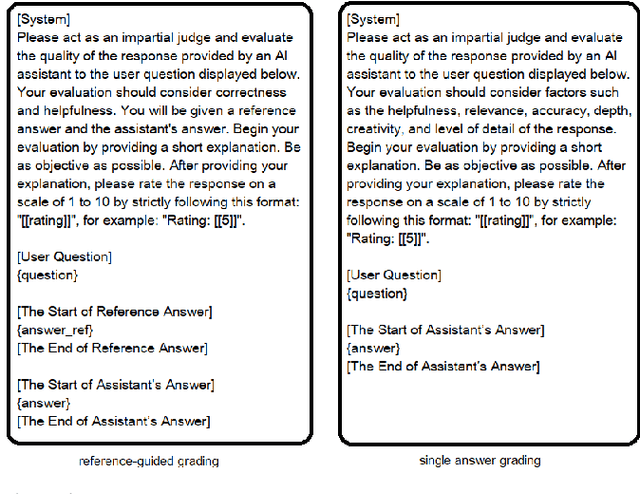
May 16, 2024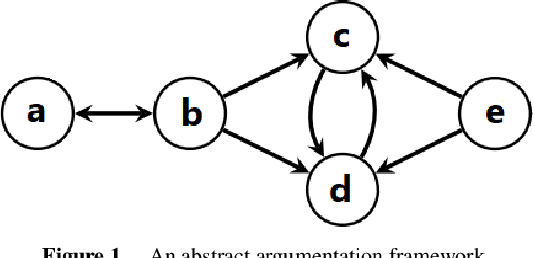


Recent years witnessed significant performance advancements in deep-learning-driven natural language models, with a strong focus on the development and release of Large Language Models (LLMs). These improvements resulted in better quality AI-generated output but rely on resource-expensive training and upgrading of models. Although different studies have proposed a range of techniques to enhance LLMs without retraining, none have considered computational argumentation as an option. This is a missed opportunity since computational argumentation is an intuitive mechanism that formally captures agents' interactions and the information conflict that may arise during such interplays, and so it seems well-suited for boosting the reasoning and conversational abilities of LLMs in a seamless manner. In this paper, we present a pipeline (MQArgEng) and preliminary study to evaluate the effect of introducing computational argumentation semantics on the performance of LLMs. Our experiment's goal was to provide a proof-of-concept and a feasibility analysis in order to foster (or deter) future research towards a fully-fledged argumentation engine plugin for LLMs. Exploratory results using the MT-Bench indicate that MQArgEng provides a moderate performance gain in most of the examined topical categories and, as such, show promise and warrant further research.
Computational Argumentation-based Chatbots: a Survey
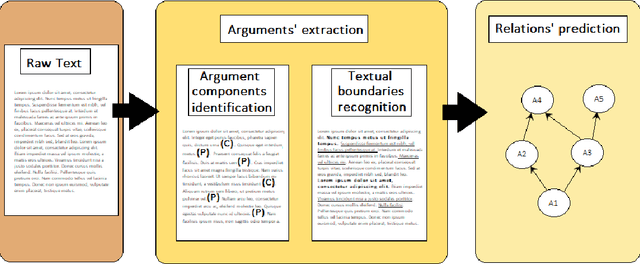
Jan 07, 2024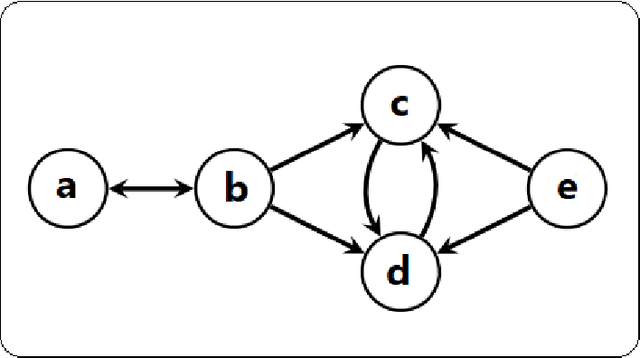


Chatbots are conversational software applications designed to interact dialectically with users for a plethora of different purposes. Surprisingly, these colloquial agents have only recently been coupled with computational models of arguments (i.e. computational argumentation), whose aim is to formalise, in a machine-readable format, the ordinary exchange of information that characterises human communications. Chatbots may employ argumentation with different degrees and in a variety of manners. The present survey sifts through the literature to review papers concerning this kind of argumentation-based bot, drawing conclusions about the benefits and drawbacks that this approach entails in comparison with standard chatbots, while also envisaging possible future development and integration with the Transformer-based architecture and state-of-the-art Large Language models.