 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeological Inference from Textual Data using Word Embeddings
Apr 10, 2025



This research explores the use of Natural Language Processing (NLP) techniques to locate geological resources, with a specific focus on industrial minerals. By using word embeddings trained with the GloVe model, we extract semantic relationships between target keywords and a corpus of geological texts. The text is filtered to retain only words with geographical significance, such as city names, which are then ranked by their cosine similarity to the target keyword. Dimensional reduction techniques, including Principal Component Analysis (PCA), Autoencoder, Variational Autoencoder (VAE), and VAE with Long Short-Term Memory (VAE-LSTM), are applied to enhance feature extraction and improve the accuracy of semantic relations. For benchmarking, we calculate the proximity between the ten cities most semantically related to the target keyword and identified mine locations using the haversine equation. The results demonstrate that combining NLP with dimensional reduction techniques provides meaningful insights into the spatial distribution of natural resources. Although the result shows to be in the same region as the supposed location, the accuracy has room for improvement.
Regression with Missing Data, a Comparison Study of TechniquesBased on Random Forests
Oct 18, 2021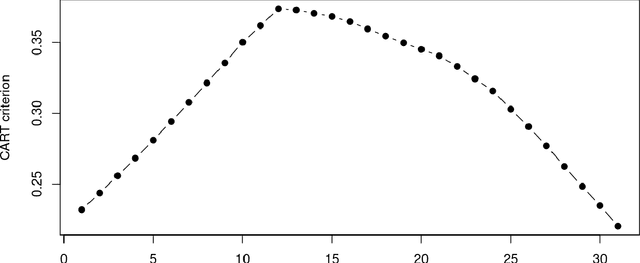
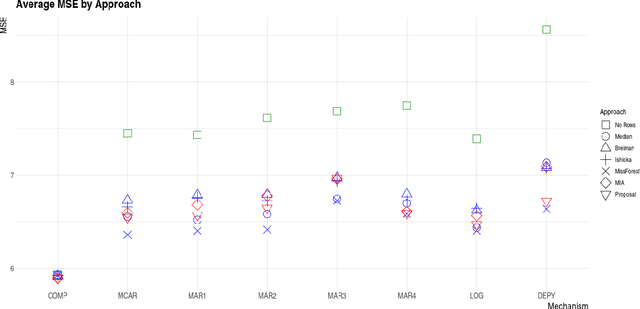
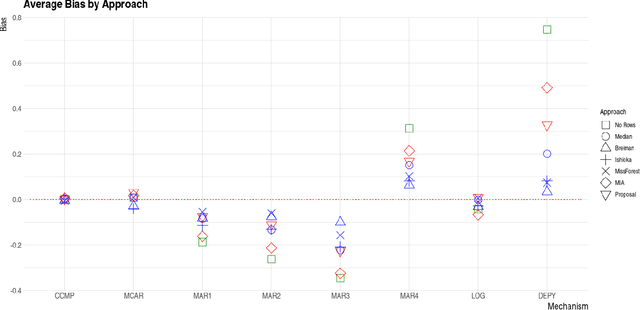
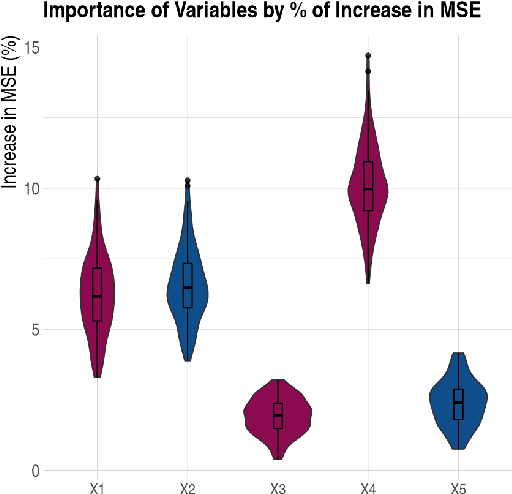
In this paper we present the practical benefits of a new random forest algorithm to deal withmissing values in the sample. The purpose of this work is to compare the different solutionsto deal with missing values with random forests and describe our new algorithm performanceas well as its algorithmic complexity. A variety of missing value mechanisms (such as MCAR,MAR, MNAR) are considered and simulated. We study the quadratic errors and the bias ofour algorithm and compare it to the most popular missing values random forests algorithms inthe literature. In particular, we compare those techniques for both a regression and predictionpurpose. This work follows a first paper Gomez-Mendez and Joly (2020) on the consistency ofthis new algorithm.