 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the ground truth? Reliability of multi-annotator data for audio tagging
Apr 09, 2021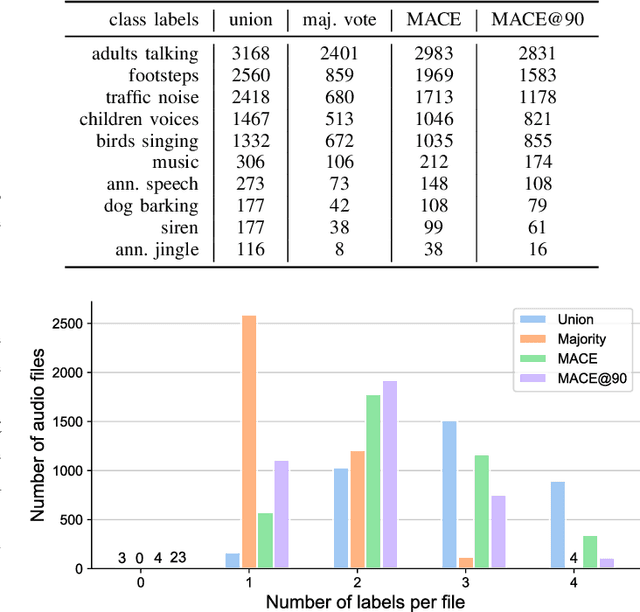
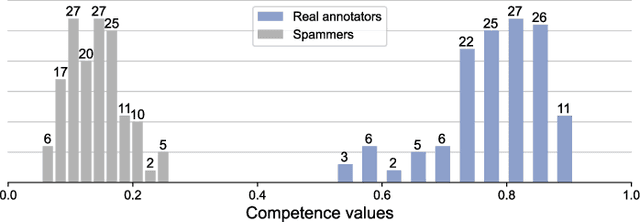

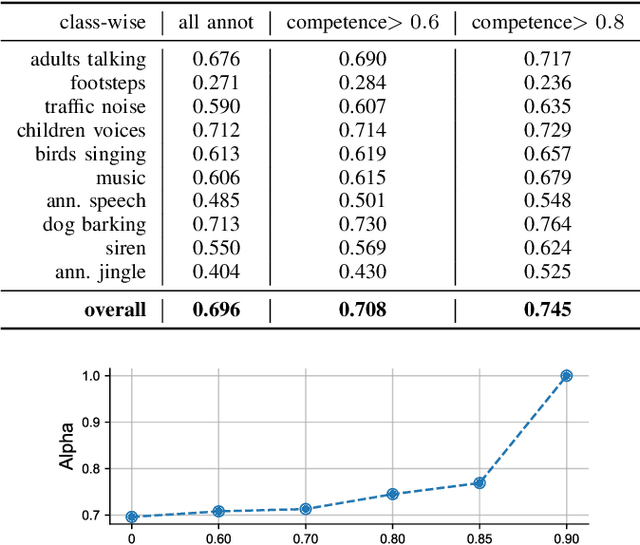
Crowdsourcing has become a common approach for annotating large amounts of data. It has the advantage of harnessing a large workforce to produce large amounts of data in a short time, but comes with the disadvantage of employing non-expert annotators with different backgrounds. This raises the problem of data reliability, in addition to the general question of how to combine the opinions of multiple annotators in order to estimate the ground truth. This paper presents a study of the annotations and annotators' reliability for audio tagging. We adapt the use of Krippendorf's alpha and multi-annotator competence estimation (MACE) for a multi-labeled data scenario, and present how MACE can be used to estimate a candidate ground truth based on annotations from non-expert users with different levels of expertise and competence.
On the performance of residual block design alternatives in convolutional neural networks for end-to-end audio classification
Jul 05, 2019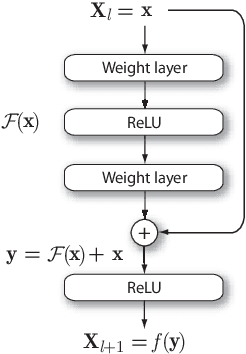

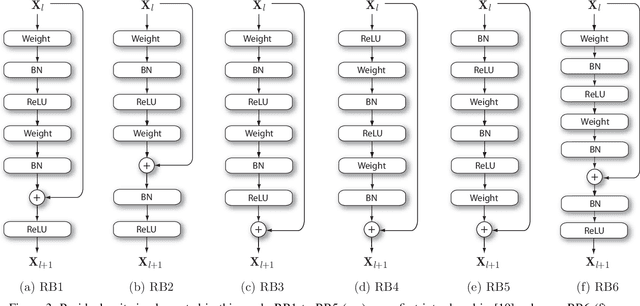

Residual learning is a recently proposed learning framework to facilitate the training of very deep neural networks. Residual blocks or units are made of a set of stacked layers, where the inputs are added back to their outputs with the aim of creating identity mappings. In practice, such identity mappings are accomplished by means of the so-called skip or residual connections. However, multiple implementation alternatives arise with respect to where such skip connections are applied within the set of stacked layers that make up a residual block. While ResNet architectures for image classification using convolutional neural networks (CNNs) have been widely discussed in the literature, few works have adopted ResNet architectures so far for 1D audio classification tasks. Thus, the suitability of different residual block designs for raw audio classification is partly unknown. The purpose of this paper is to analyze and discuss the performance of several residual block implementations within a state-of-the-art CNN-based architecture for end-to-end audio classification using raw audio waveforms. For comparison purposes, we analyze as well the performance of the residual blocks under a similar 2D architecture using a conventional time-frequency audio represen-tation as input. The results show that the achieved accuracy is considerably dependent, not only on the specific residual block implementation, but also on the selected input normalization.