 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Model Identification Using Audio and Visual Content from Videos
Jun 25, 2024

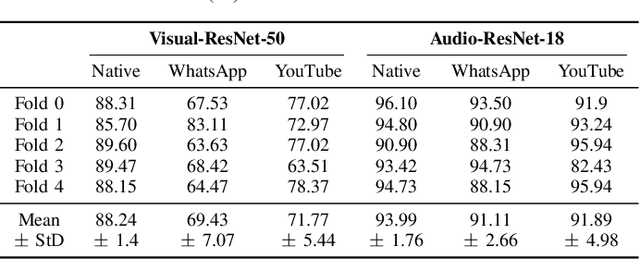
The identification of device brands and models plays a pivotal role in the realm of multimedia forensic applications. This paper presents a framework capable of identifying devices using audio, visual content, or a fusion of them. The fusion of visual and audio content occurs later by applying two fundamental fusion rules: the product and the sum. The device identification problem is tackled as a classification one by leveraging Convolutional Neural Networks. Experimental evaluation illustrates that the proposed framework exhibits promising classification performance when independently using audio or visual content. Furthermore, although the fusion results don't consistently surpass both individual modalities, they demonstrate promising potential for enhancing classification performance. Future research could refine the fusion process to improve classification performance in both modalities consistently. Finally, a statistical significance test is performed for a more in-depth study of the classification results.