 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Cluster-based Federated Learning
Jan 29, 2025



As the industrial and commercial use of Federated Learning (FL) has expanded, so has the need for optimized algorithms. In settings were FL clients' data is non-independently and identically distributed (non-IID) and with highly heterogeneous distributions, the baseline FL approach seems to fall short. To tackle this issue, recent studies, have looked into personalized FL (PFL) which relaxes the implicit single-model constraint and allows for multiple hypotheses to be learned from the data or local models. Among the personalized FL approaches, cluster-based solutions (CFL) are particularly interesting whenever it is clear -through domain knowledge -that the clients can be separated into groups. In this paper, we study recent works on CFL, proposing: i) a classification of CFL solutions for personalization; ii) a structured review of literature iii) a review of alternative use cases for CFL. CCS Concepts: $\bullet$ General and reference $\rightarrow$ Surveys and overviews; $\bullet$ Computing methodologies $\rightarrow$ Machine learning; $\bullet$ Information systems $\rightarrow$ Clustering; $\bullet$ Security and privacy $\rightarrow$ Privacy-preserving protocols.
Comparative Evaluation of Clustered Federated Learning Method
Oct 18, 2024
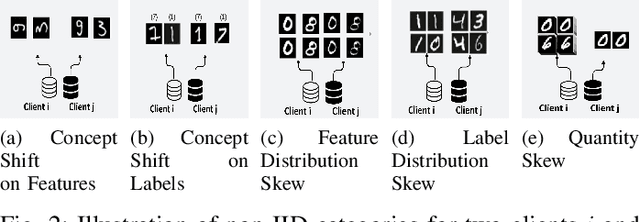


Over recent years, Federated Learning (FL) has proven to be one of the most promising methods of distributed learning which preserves data privacy. As the method evolved and was confronted to various real-world scenarios, new challenges have emerged. One such challenge is the presence of highly heterogeneous (often referred as non-IID) data distributions among participants of the FL protocol. A popular solution to this hurdle is Clustered Federated Learning (CFL), which aims to partition clients into groups where the distribution are homogeneous. In the literature, state-of-the-art CFL algorithms are often tested using a few cases of data heterogeneities, without systematically justifying the choices. Further, the taxonomy used for differentiating the different heterogeneity scenarios is not always straightforward. In this paper, we explore the performance of two state-of-theart CFL algorithms with respect to a proposed taxonomy of data heterogeneities in federated learning (FL). We work with three image classification datasets and analyze the resulting clusters against the heterogeneity classes using extrinsic clustering metrics. Our objective is to provide a clearer understanding of the relationship between CFL performances and data heterogeneity scenarios.