 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep metric learning improves lab of origin prediction of genetically engineered plasmids
Nov 24, 2021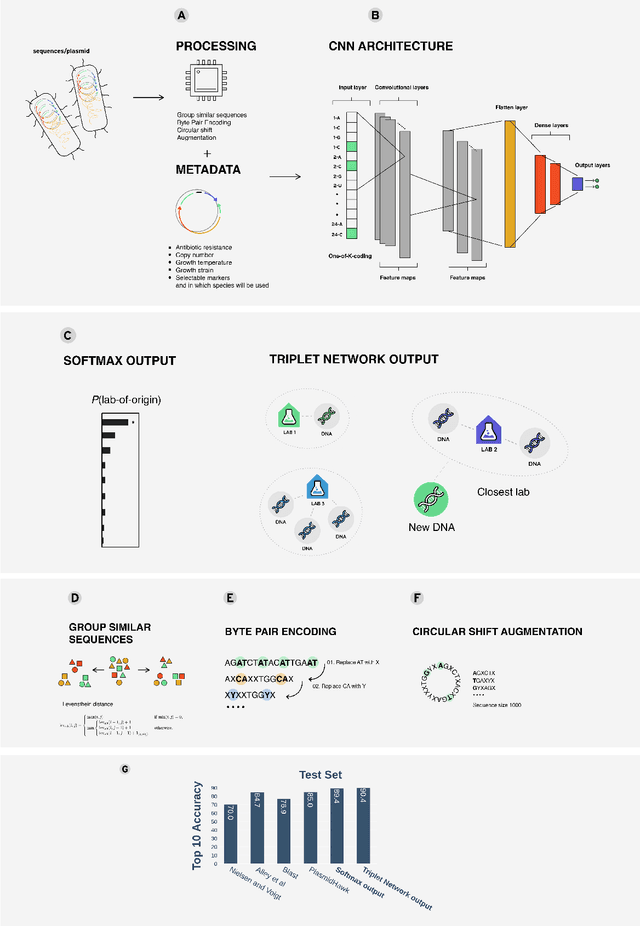
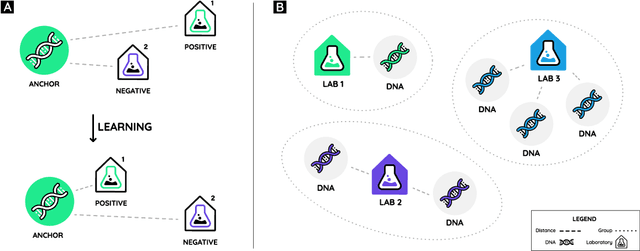
Genome engineering is undergoing unprecedented development and is now becoming widely available. To ensure responsible biotechnology innovation and to reduce misuse of engineered DNA sequences, it is vital to develop tools to identify the lab-of-origin of engineered plasmids. Genetic engineering attribution (GEA), the ability to make sequence-lab associations, would support forensic experts in this process. Here, we propose a method, based on metric learning, that ranks the most likely labs-of-origin whilst simultaneously generating embeddings for plasmid sequences and labs. These embeddings can be used to perform various downstream tasks, such as clustering DNA sequences and labs, as well as using them as features in machine learning models. Our approach employs a circular shift augmentation approach and is able to correctly rank the lab-of-origin $90\%$ of the time within its top 10 predictions - outperforming all current state-of-the-art approaches. We also demonstrate that we can perform few-shot-learning and obtain $76\%$ top-10 accuracy using only $10\%$ of the sequences. This means, we outperform the previous CNN approach using only one-tenth of the data. We also demonstrate that we are able to extract key signatures in plasmid sequences for particular labs, allowing for an interpretable examination of the model's outputs.