 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Scale Survey of Motivation in Software Development and Analysis of its Validity
Apr 12, 2024Context: Motivation is known to improve performance. In software development in particular, there has been considerable interest in the motivation of contributors to open source. Objective: We identify 11 motivators from the literature (enjoying programming, ownership of code, learning, self use, etc.), and evaluate their relative effect on motivation. Since motivation is an internal subjective feeling, we also analyze the validity of the answers. Method: We conducted a survey with 66 questions on motivation which was completed by 521 developers. Most of the questions used an 11 point scale. We evaluated the validity of the answers validity by comparing related questions, comparing to actual behavior on GitHub, and comparison with the same developer in a follow up survey. Results: Validity problems include moderate correlations between answers to related questions, as well as self promotion and mistakes in the answers. Despite these problems, predictive analysis, investigating how diverse motivators influence the probability of high motivation, provided valuable insights. The correlations between the different motivators are low, implying their independence. High values in all 11 motivators predict increased probability of high motivation. In addition, improvement analysis shows that an increase in most motivators predicts an increase in general motivation.
End to End Software Engineering Research
Dec 22, 2021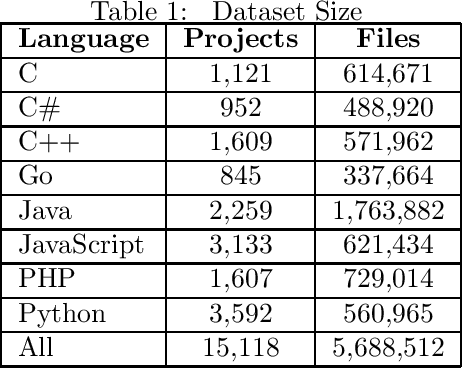

End to end learning is machine learning starting in raw data and predicting a desired concept, with all steps done automatically. In software engineering context, we see it as starting from the source code and predicting process metrics. This framework can be used for predicting defects, code quality, productivity and more. End-to-end improves over features based machine learning by not requiring domain experts and being able to extract new knowledge. We describe a dataset of 5M files from 15k projects constructed for this goal. The dataset is constructed in a way that enables not only predicting concepts but also investigating their causes.
ComSum: Commit Messages Summarization and Meaning Preservation
Aug 23, 2021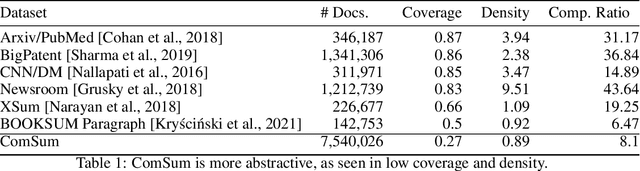


We present ComSum, a data set of 7 million commit messages for text summarization. When documenting commits, software code changes, both a message and its summary are posted. We gather and filter those to curate developers' work summarization data set. Along with its growing size, practicality and challenging language domain, the data set benefits from the living field of empirical software engineering. As commits follow a typology, we propose to not only evaluate outputs by Rouge, but by their meaning preservation.
Follow Your Nose -- Which Code Smells are Worth Chasing?
Mar 02, 2021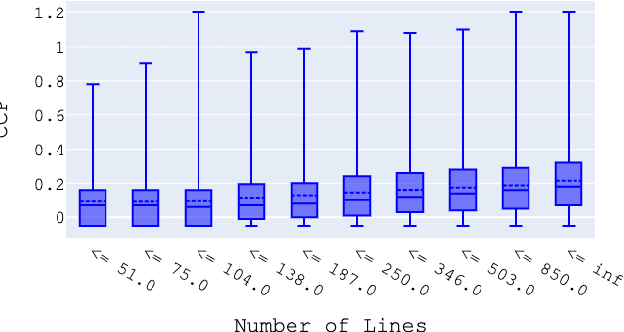
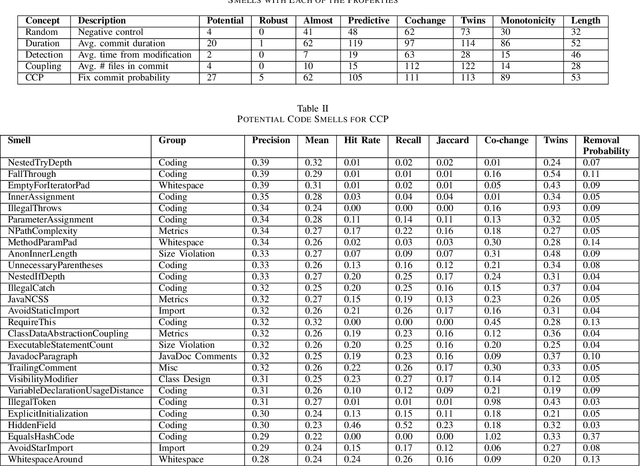
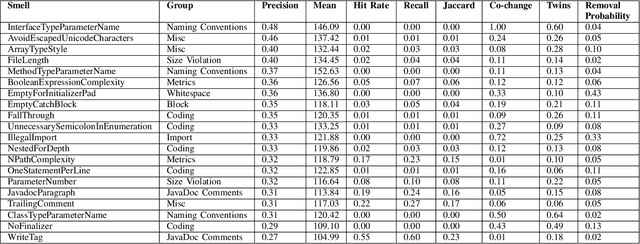
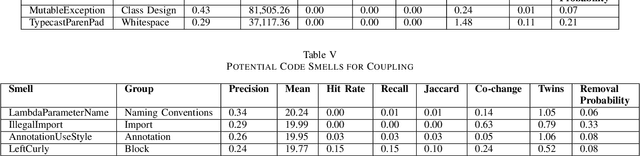
The common use case of code smells assumes causality: Identify a smell, remove it, and by doing so improve the code. We empirically investigate their fitness to this use. We present a list of properties that code smells should have if they indeed cause lower quality. We evaluated the smells in 31,687 Java files from 677 GitHub repositories, all the repositories with 200+ commits in 2019. We measured the influence of smells on four metrics for quality, productivity, and bug detection efficiency. Out of 151 code smells computed by the CheckStyle smell detector, less than 20% were found to be potentially causal, and only a handful are rather robust. The strongest smells deal with simplicity, defensive programming, and abstraction. Files without the potentially causal smells are 50% more likely to be of high quality. Unfortunately, most smells are not removed, and developers tend to remove the easy ones and not the effective ones.
The Corrective Commit Probability Code Quality Metric
Jul 21, 2020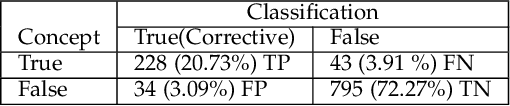
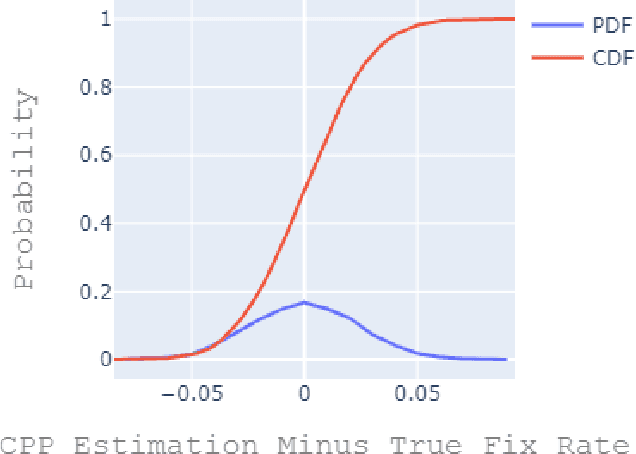
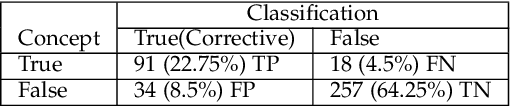
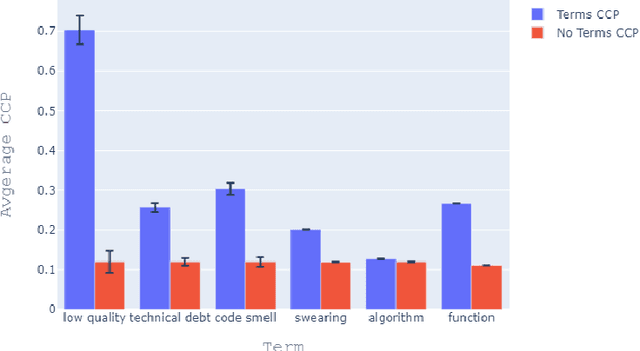
We present a code quality metric, Corrective Commit Probability (CCP), measuring the probability that a commit reflects corrective maintenance. We show that this metric agrees with developers' concept of quality, informative, and stable. Corrective commits are identified by applying a linguistic model to the commit messages. Corrective commits are identified by applying a linguistic model to the commit messages. We compute the CCP of all large active GitHub projects (7,557 projects with at least 200 commits in 2019). This leads to the creation of a quality scale, suggesting that the bottom 10% of quality projects spend at least 6 times more effort on fixing bugs than the top 10%. Analysis of project attributes shows that lower CCP (higher quality) is associated with smaller files, lower coupling, use of languages like JavaScript and C# as opposed to PHP and C++, fewer developers, lower developer churn, better onboarding, and better productivity. Among other things these results support the "Quality is Free" claim, and suggest that achieving higher quality need not require higher expenses.
Machine Learning in Cyber-Security - Problems, Challenges and Data Sets
Dec 19, 2018We present cyber-security problems of high importance. We show that in order to solve these cyber-security problems, one must cope with certain machine learning challenges. We provide novel data sets representing the problems in order to enable the academic community to investigate the problems and suggest methods to cope with the challenges. We also present a method to generate labels via pivoting, providing a solution to common problems of lack of labels in cyber-security.