Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to End Software Engineering Research
Paper and Code
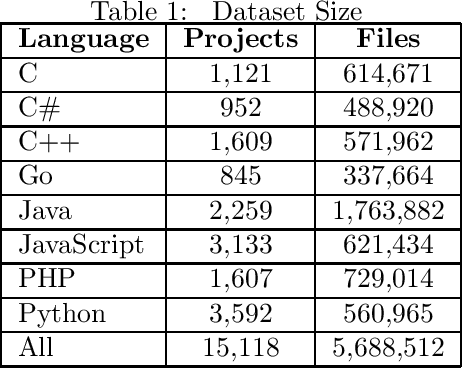

End to end learning is machine learning starting in raw data and predicting a desired concept, with all steps done automatically. In software engineering context, we see it as starting from the source code and predicting process metrics. This framework can be used for predicting defects, code quality, productivity and more. End-to-end improves over features based machine learning by not requiring domain experts and being able to extract new knowledge. We describe a dataset of 5M files from 15k projects constructed for this goal. The dataset is constructed in a way that enables not only predicting concepts but also investigating their causes.
View paper on