 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Learning Analysis of Social Politics using Knowledge Graph Embedding
Jun 02, 2020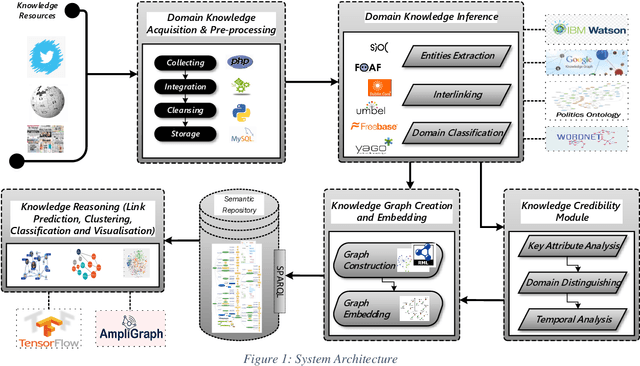
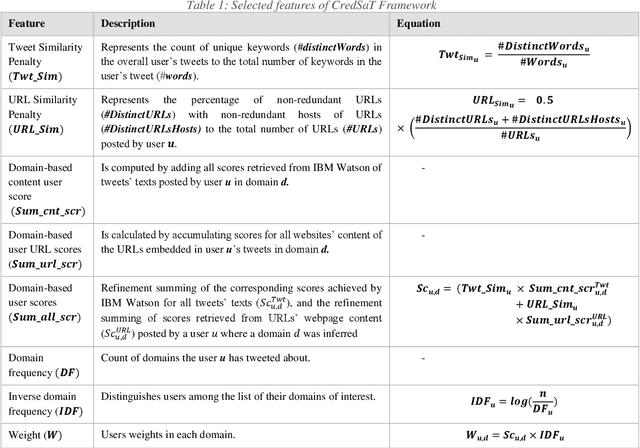
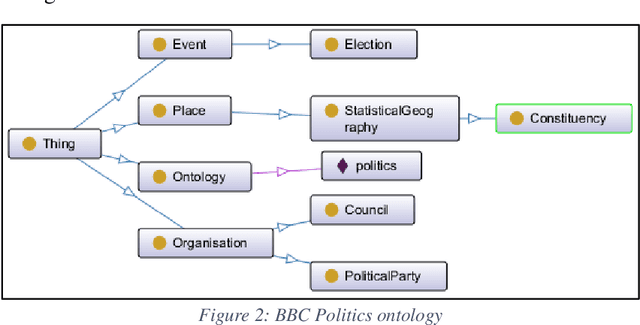
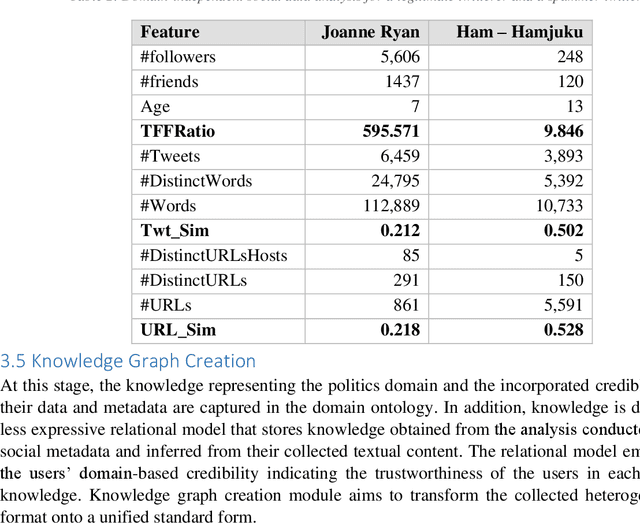
Knowledge Graphs (KGs) have gained considerable attention recently from both academia and industry. In fact, incorporating graph technology and the copious of various graph datasets have led the research community to build sophisticated graph analytics tools. Therefore, the application of KGs has extended to tackle a plethora of real-life problems in dissimilar domains. Despite the abundance of the currently proliferated generic KGs, there is a vital need to construct domain-specific KGs. Further, quality and credibility should be assimilated in the process of constructing and augmenting KGs, particularly those propagated from mixed-quality resources such as social media data. This paper presents a novel credibility domain-based KG Embedding framework. This framework involves capturing a fusion of data obtained from heterogeneous resources into a formal KG representation depicted by a domain ontology. The proposed approach makes use of various knowledge-based repositories to enrich the semantics of the textual contents, thereby facilitating the interoperability of information. The proposed framework also embodies a credibility module to ensure data quality and trustworthiness. The constructed KG is then embedded in a low-dimension semantically-continuous space using several embedding techniques. The utility of the constructed KG and its embeddings is demonstrated and substantiated on link prediction, clustering, and visualisation tasks.
Sentiment analysis for Arabic language: A brief survey of approaches and techniques
Sep 15, 2018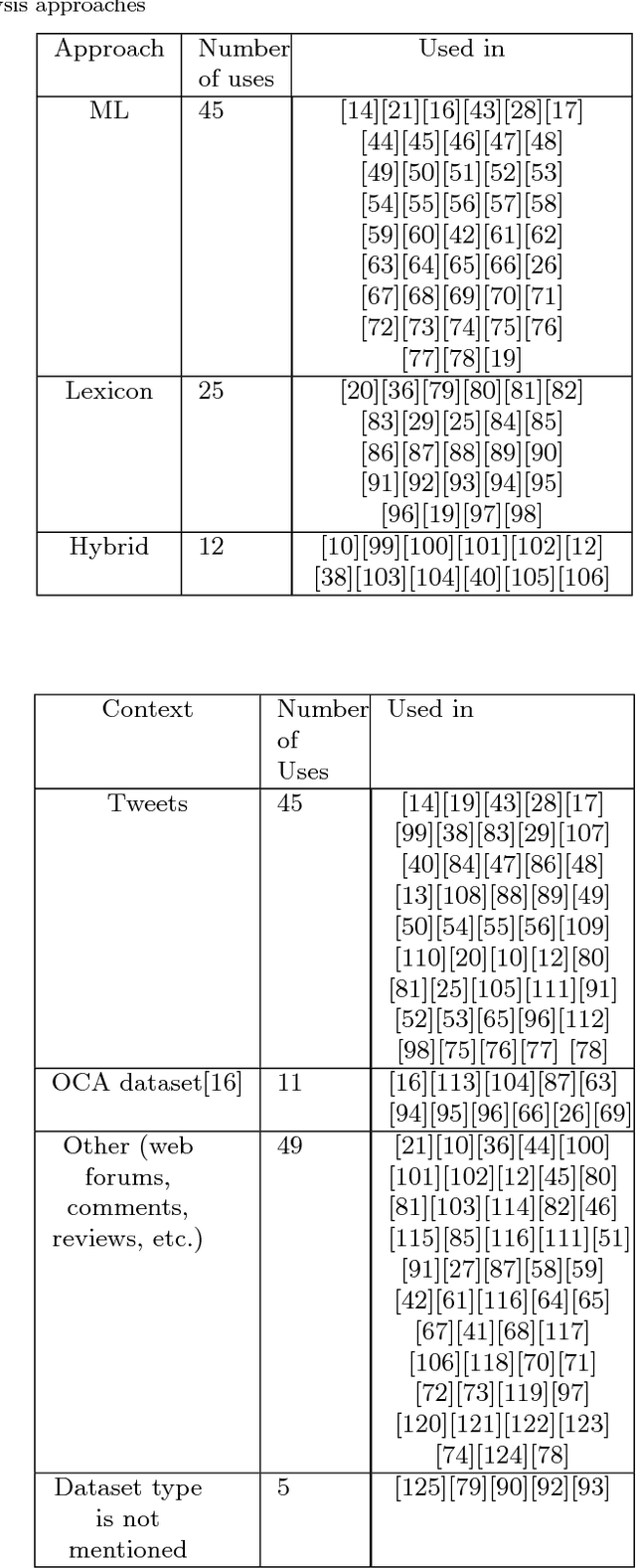
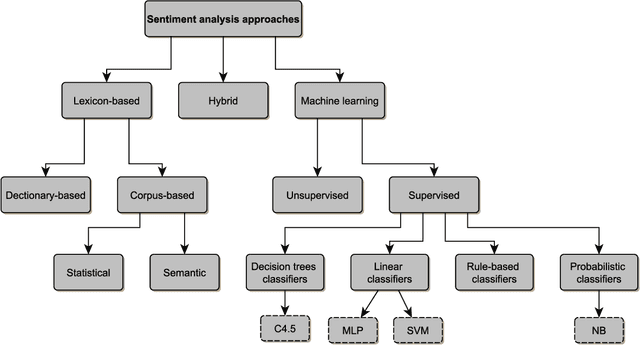
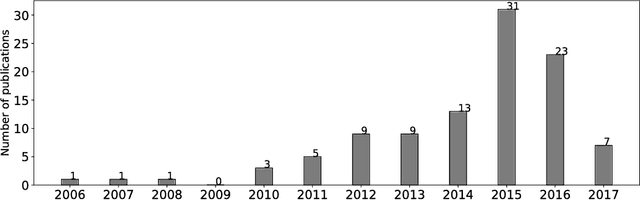
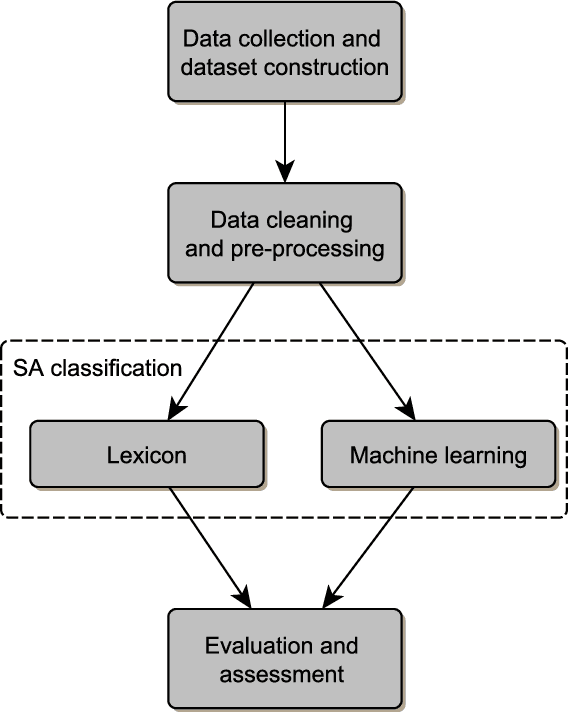
With the emergence of Web 2.0 technology and the expansion of on-line social networks, current Internet users have the ability to add their reviews, ratings and opinions on social media and on commercial and news web sites. Sentiment analysis aims to classify these reviews reviews in an automatic way. In the literature, there are numerous approaches proposed for automatic sentiment analysis for different language contexts. Each language has its own properties that makes the sentiment analysis more challenging. In this regard, this work presents a comprehensive survey of existing Arabic sentiment analysis studies, and covers the various approaches and techniques proposed in the literature. Moreover, we highlight the main difficulties and challenges of Arabic sentiment analysis, and the proposed techniques in literature to overcome these barriers.
EMFET: E-mail Features Extraction Tool
Nov 22, 2017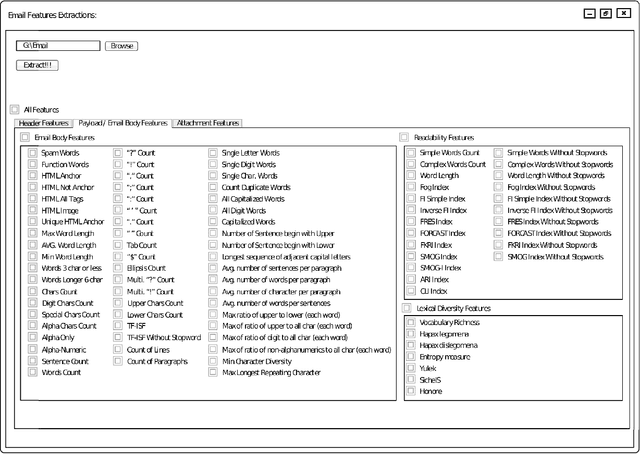
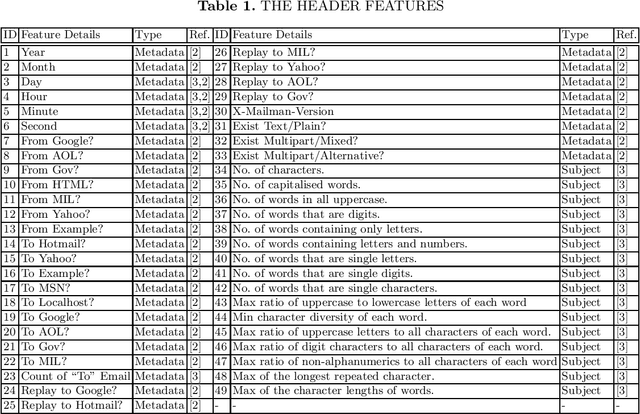
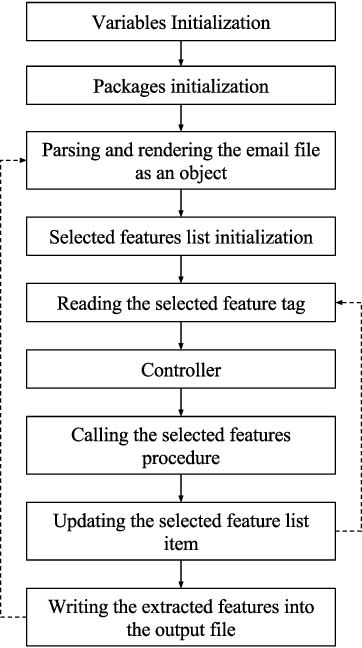
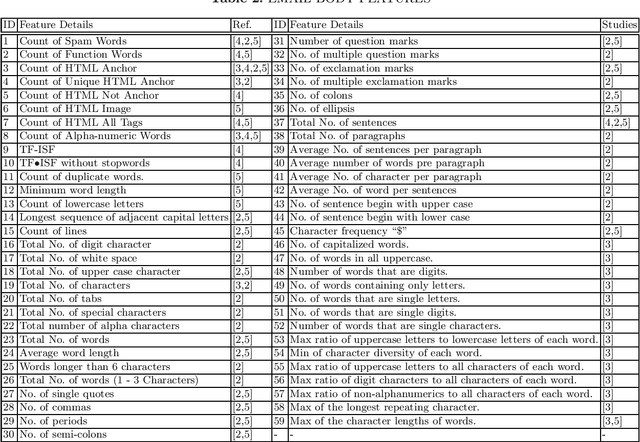
EMFET is an open source and flexible tool that can be used to extract a large number of features from any email corpus with emails saved in EML format. The extracted features can be categorized into three main groups: header features, payload (body) features, and attachment features. The purpose of the tool is to help practitioners and researchers to build datasets that can be used for training machine learning models for spam detection. So far, 140 features can be extracted using EMFET. EMFET is extensible and easy to use. The source code of EMFET is publicly available at GitHub (https://github.com/WadeaHijjawi/EmailFeaturesExtraction)