 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary BP+OSD Decoding for Low-Latency Quantum Error Correction
Dec 20, 2025We propose an evolutionary belief propagation (EBP) decoder for quantum error correction, which incorporates trainable weights into the BP algorithm and optimizes them via the differential evolution algorithm. This approach enables end-to-end optimization of the EBP combined with ordered statistics decoding (OSD). Experimental results on surface codes and quantum low-density parity-check codes show that EBP+OSD achieves better decoding performance and lower computational complexity than BP+OSD, particularly under strict low latency constraints (within 5 BP iterations).
Episodic Memory Reader: Learning What to Remember for Question Answering from Streaming Data
Mar 18, 2019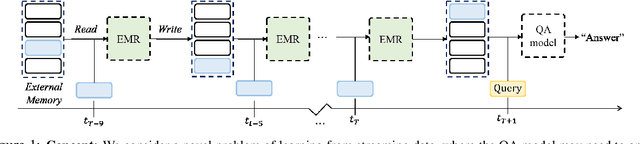
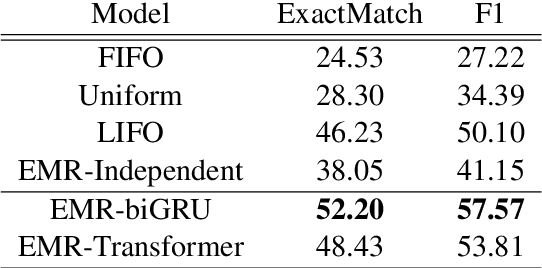
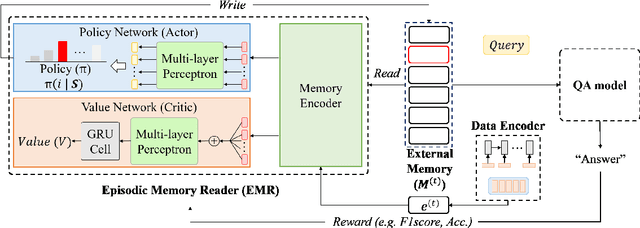
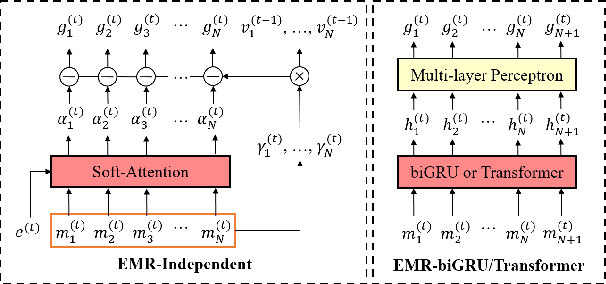
We consider a novel question answering (QA) task where the machine needs to read from large streaming data (long documents or videos) without knowing when the questions will be given, in which case the existing QA methods fail due to lack of scalability. To tackle this problem, we propose a novel end-to-end reading comprehension method, which we refer to as Episodic Memory Reader (EMR) that sequentially reads the input contexts into an external memory, while replacing memories that are less important for answering unseen questions. Specifically, we train an RL agent to replace a memory entry when the memory is full in order to maximize its QA accuracy at a future timepoint, while encoding the external memory using the transformer architecture to learn representations that considers relative importance between the memory entries. We validate our model on a real-world large-scale textual QA task (TriviaQA) and a video QA task (TVQA), on which it achieves significant improvements over rule-based memory scheduling policies or an RL-based baseline that learns the query-specific importance of each memory independently.
Learning What to Remember: Long-term Episodic Memory Networks for Learning from Streaming Data
Dec 11, 2018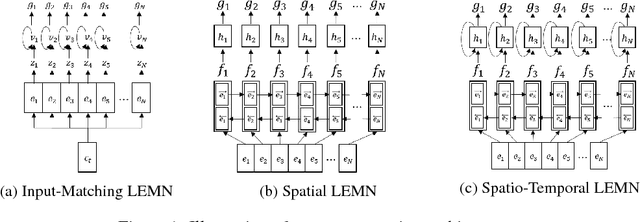

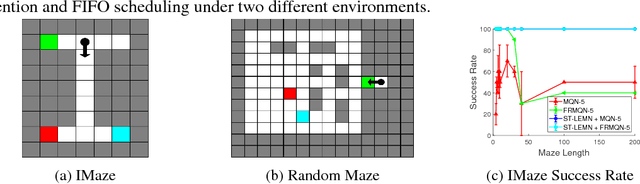
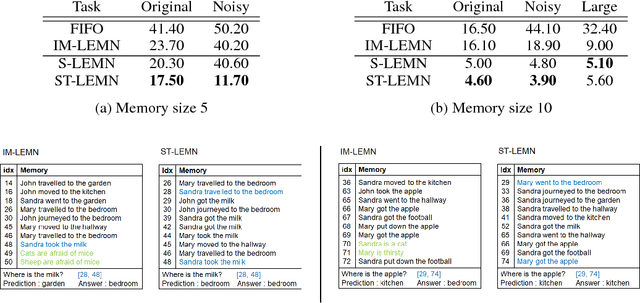
Current generation of memory-augmented neural networks has limited scalability as they cannot efficiently process data that are too large to fit in the external memory storage. One example of this is lifelong learning scenario where the model receives unlimited length of data stream as an input which contains vast majority of uninformative entries. We tackle this problem by proposing a memory network fit for long-term lifelong learning scenario, which we refer to as Long-term Episodic Memory Networks (LEMN), that features a RNN-based retention agent that learns to replace less important memory entries based on the retention probability generated on each entry that is learned to identify data instances of generic importance relative to other memory entries, as well as its historical importance. Such learning of retention agent allows our long-term episodic memory network to retain memory entries of generic importance for a given task. We validate our model on a path-finding task as well as synthetic and real question answering tasks, on which our model achieves significant improvements over the memory augmented networks with rule-based memory scheduling as well as an RL-based baseline that does not consider relative or historical importance of the memory.