 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvival regression with accelerated failure time model in XGBoost
Jun 11, 2020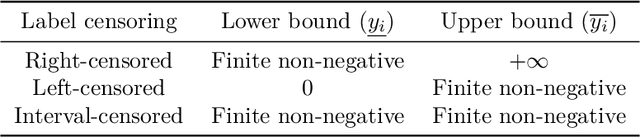
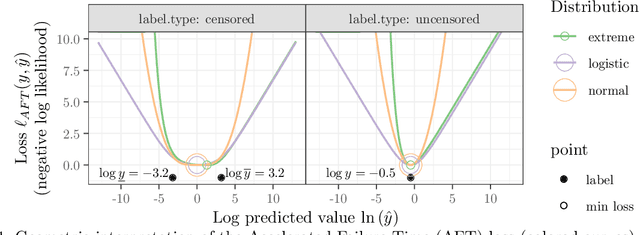

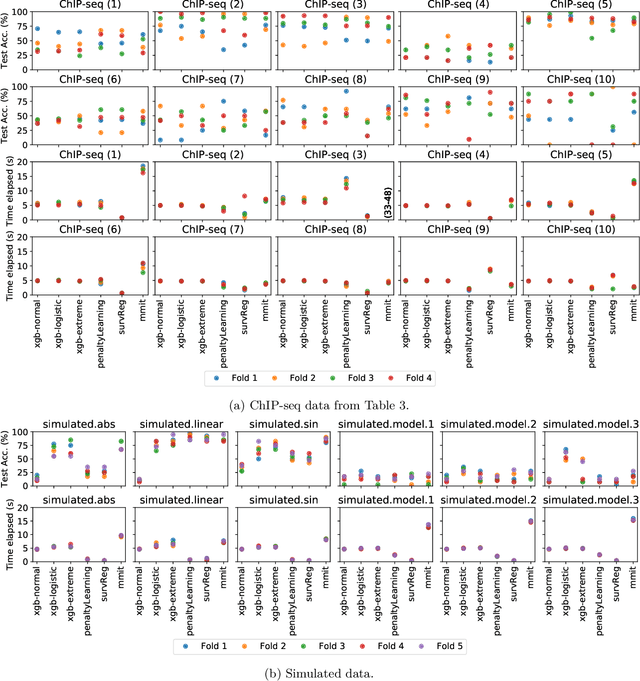
Survival regression is used to estimate the relation between time-to-event and feature variables, and is important in application domains such as medicine, marketing, risk management and sales management. Nonlinear tree based machine learning algorithms as implemented in libraries such as XGBoost, scikit-learn, LightGBM, and CatBoost are often more accurate in practice than linear models. However, existing implementations of tree-based models have offered limited support for survival regression. In this work, we propose and implement loss functions for learning accelerated failure time (AFT) models in XGBoost, to increase the support for survival modeling for different kinds of label censoring. The AFT model assumes effects that directly accelerate or decelerate the survival time for different kinds of censored data sets. We demonstrate with real and simulated experiments the effectiveness of AFT in XGBoost with respect to a number of baselines, in two respects: generalization performance and training speed. Furthermore, we take advantage of the support for NVIDIA GPUs in XGBoost to achieve substantial speedup over multi-coreCPUs. To our knowledge, our work is the first implementation of AFT that utilizes the processing power of NVIDIA GPUs.
Block-distributed Gradient Boosted Trees
May 28, 2019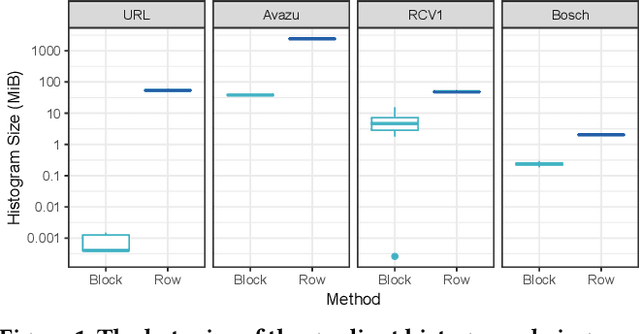
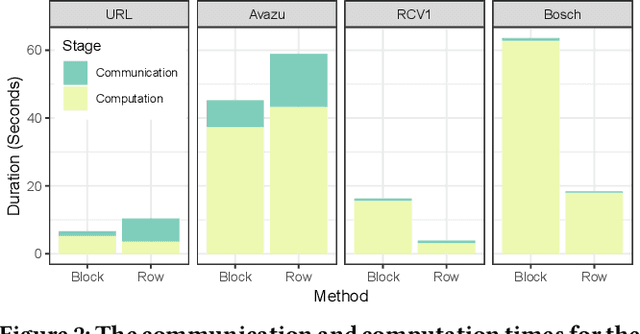
The Gradient Boosted Tree (GBT) algorithm is one of the most popular machine learning algorithms used in production, for tasks that include Click-Through Rate (CTR) prediction and learning-to-rank. To deal with the massive datasets available today, many distributed GBT methods have been proposed. However, they all assume a row-distributed dataset, addressing scalability only with respect to the number of data points and not the number of features, and increasing communication cost for high-dimensional data. In order to allow for scalability across both the data point and feature dimensions, and reduce communication cost, we propose block-distributed GBTs. We achieve communication efficiency by making full use of the data sparsity and adapting the Quickscorer algorithm to the block-distributed setting. We evaluate our approach using datasets with millions of features, and demonstrate that we are able to achieve multiple orders of magnitude reduction in communication cost for sparse data, with no loss in accuracy, while providing a more scalable design. As a result, we are able to reduce the training time for high-dimensional data, and allow more cost-effective scale-out without the need for expensive network communication.