 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Heterogeneous Treatment Effect with Instrumental Variables
Aug 09, 2019
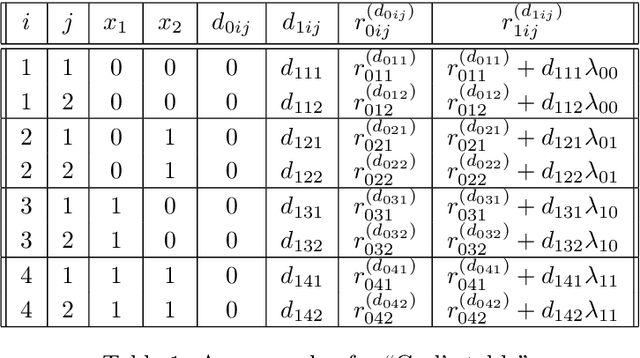

There is an increasing interest in estimating heterogeneity in causal effects in randomized and observational studies. However, little research has been conducted to understand heterogeneity in an instrumental variables study. In this work, we present a method to estimate heterogeneous causal effects using an instrumental variable approach. The method has two parts. The first part uses subject-matter knowledge and interpretable machine learning techniques, such as classification and regression trees, to discover potential effect modifiers. The second part uses closed testing to test for the statistical significance of the effect modifiers while strongly controlling familywise error rate. We conducted this method on the Oregon Health Insurance Experiment, estimating the effect of Medicaid on the number of days an individual's health does not impede their usual activities, and found evidence of heterogeneity in older men who prefer English and don't self-identify as Asian and younger individuals who have at most a high school diploma or GED and prefer English.
Estimating Treatment Effects using Multiple Surrogates: The Role of the Surrogate Score and the Surrogate Index
Jun 04, 2016



Estimating the long-term effects of treatments is of interest in many fields. A common challenge in estimating such treatment effects is that long-term outcomes are unobserved in the time frame needed to make policy decisions. One approach to overcome this missing data problem is to analyze treatments effects on an intermediate outcome, often called a statistical surrogate, if it satisfies the condition that treatment and outcome are independent conditional on the statistical surrogate. The validity of the surrogacy condition is often controversial. Here we exploit that fact that in modern datasets, researchers often observe a large number, possibly hundreds or thousands, of intermediate outcomes, thought to lie on or close to the causal chain between the treatment and the long-term outcome of interest. Even if none of the individual proxies satisfies the statistical surrogacy criterion by itself, using multiple proxies can be useful in causal inference. We focus primarily on a setting with two samples, an experimental sample containing data about the treatment indicator and the surrogates and an observational sample containing information about the surrogates and the primary outcome. We state assumptions under which the average treatment effect be identified and estimated with a high-dimensional vector of proxies that collectively satisfy the surrogacy assumption, and derive the bias from violations of the surrogacy assumption, and show that even if the primary outcome is also observed in the experimental sample, there is still information to be gained from using surrogates.