 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Measures and Efficient Evaluation Algorithms for Large-Scale High-Dimensional Data
Jan 05, 2021
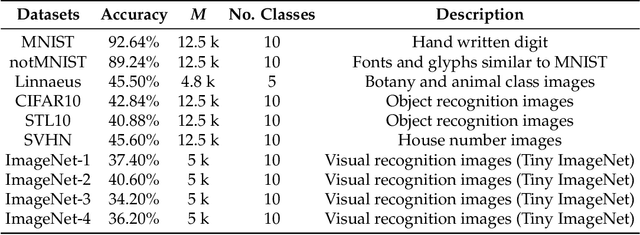
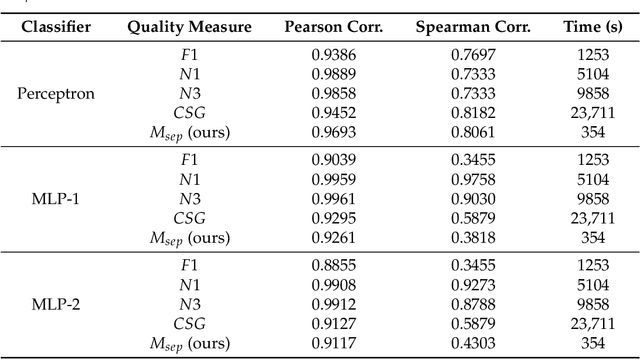
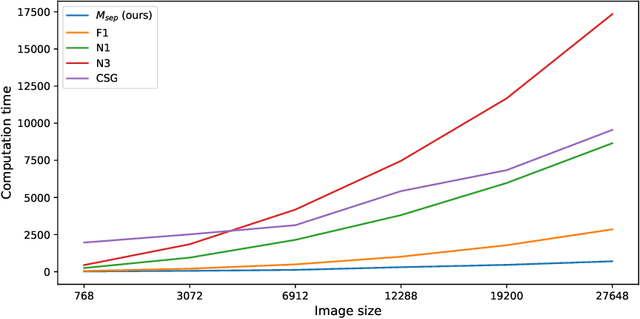
Machine learning has been proven to be effective in various application areas, such as object and speech recognition on mobile systems. Since a critical key to machine learning success is the availability of large training data, many datasets are being disclosed and published online. From a data consumer or manager point of view, measuring data quality is an important first step in the learning process. We need to determine which datasets to use, update, and maintain. However, not many practical ways to measure data quality are available today, especially when it comes to large-scale high-dimensional data, such as images and videos. This paper proposes two data quality measures that can compute class separability and in-class variability, the two important aspects of data quality, for a given dataset. Classical data quality measures tend to focus only on class separability; however, we suggest that in-class variability is another important data quality factor. We provide efficient algorithms to compute our quality measures based on random projections and bootstrapping with statistical benefits on large-scale high-dimensional data. In experiments, we show that our measures are compatible with classical measures on small-scale data and can be computed much more efficiently on large-scale high-dimensional datasets.