 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspecting class hierarchies in classification-based metric learning models
Jan 26, 2023



Most classification models treat all misclassifications equally. However, different classes may be related, and these hierarchical relationships must be considered in some classification problems. These problems can be addressed by using hierarchical information during training. Unfortunately, this information is not available for all datasets. Many classification-based metric learning methods use class representatives in embedding space to represent different classes. The relationships among the learned class representatives can then be used to estimate class hierarchical structures. If we have a predefined class hierarchy, the learned class representatives can be assessed to determine whether the metric learning model learned semantic distances that match our prior knowledge. In this work, we train a softmax classifier and three metric learning models with several training options on benchmark and real-world datasets. In addition to the standard classification accuracy, we evaluate the hierarchical inference performance by inspecting learned class representatives and the hierarchy-informed performance, i.e., the classification performance, and the metric learning performance by considering predefined hierarchical structures. Furthermore, we investigate how the considered measures are affected by various models and training options. When our proposed ProxyDR model is trained without using predefined hierarchical structures, the hierarchical inference performance is significantly better than that of the popular NormFace model. Additionally, our model enhances some hierarchy-informed performance measures under the same training options. We also found that convolutional neural networks (CNNs) with random weights correspond to the predefined hierarchies better than random chance.
Distance-Ratio-Based Formulation for Metric Learning
Jan 21, 2022In metric learning, the goal is to learn an embedding so that data points with the same class are close to each other and data points with different classes are far apart. We propose a distance-ratio-based (DR) formulation for metric learning. Like softmax-based formulation for metric learning, it models $p(y=c|x')$, which is a probability that a query point $x'$ belongs to a class $c$. The DR formulation has two useful properties. First, the corresponding loss is not affected by scale changes of an embedding. Second, it outputs the optimal (maximum or minimum) classification confidence scores on representing points for classes. To demonstrate the effectiveness of our formulation, we conduct few-shot classification experiments using softmax-based and DR formulations on CUB and mini-ImageNet datasets. The results show that DR formulation generally enables faster and more stable metric learning than the softmax-based formulation. As a result, using DR formulation achieves improved or comparable generalization performances.
Proper measure for adversarial robustness
May 06, 2020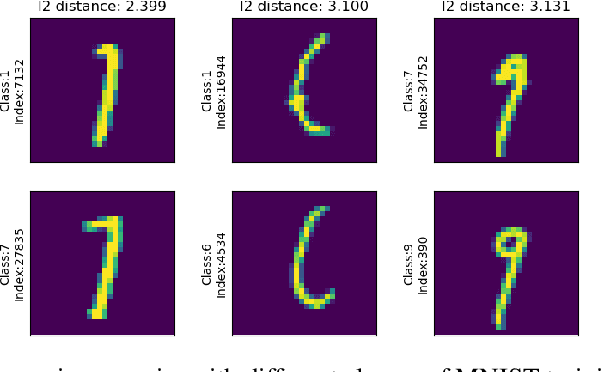
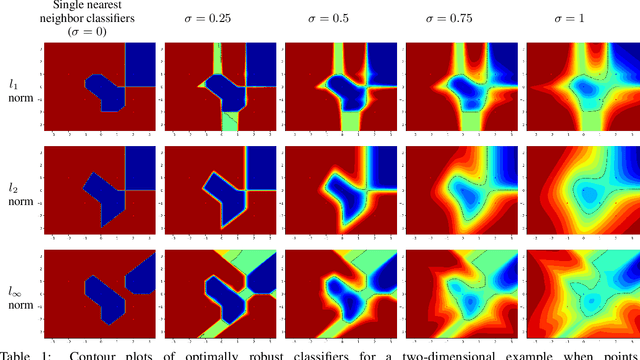
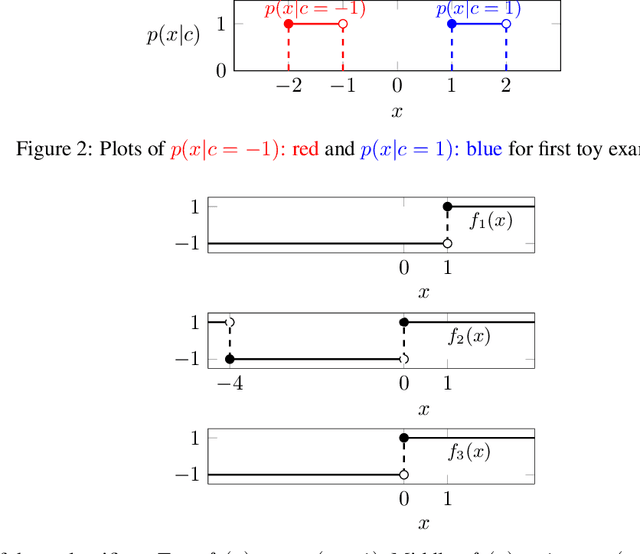
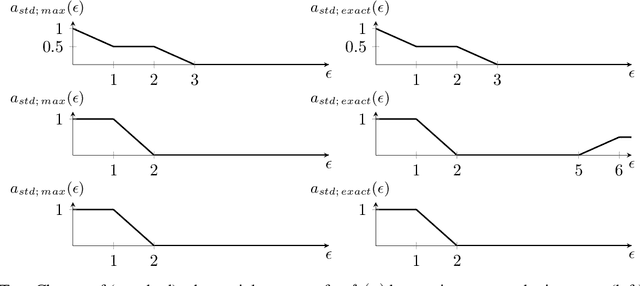
This paper analyzes the problems of standard adversarial accuracy and standard adversarial training method. We argue that standard adversarial accuracy fails to properly measure the robustness of classifiers. The definition allows overlaps in regions for clean samples and adversarial examples. Thus, there is a trade-off between accuracy and standard adversarial accuracy. Hence, using standard adversarial training can result in lowered accuracy. Also, standard adversarial accuracy can favor classifiers with more invariance-based adversarial examples, samples whose predicted classes are unchanged even if the perceptual classes are changed. In this paper, we introduce a new measure for the robustness of classifiers called genuine adversarial accuracy in order to handle the problems of the standard adversarial accuracy. It can measure adversarial robustness of classifiers without the trade-off between accuracy on clean data and adversarially perturbed samples. In addition, it doesn't favor a model with invariance-based adversarial examples. We show that a single nearest neighbor (1-NN) classifier is the most robust classifier according to genuine adversarial accuracy for given data and a metric when exclusive belongingness assumption is used. This result provides a fundamental step to train adversarially robust classifiers.
Beyond image classification: zooplankton identification with deep vector space embeddings
Sep 25, 2019

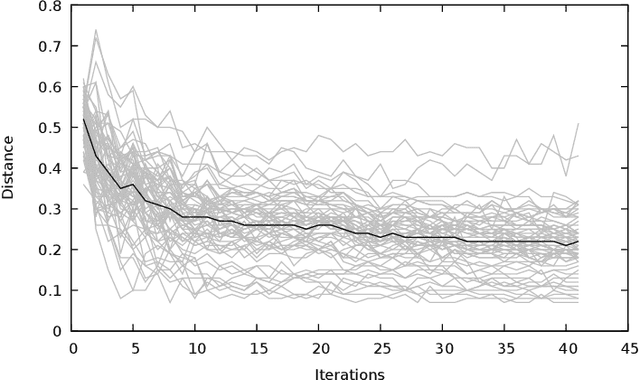
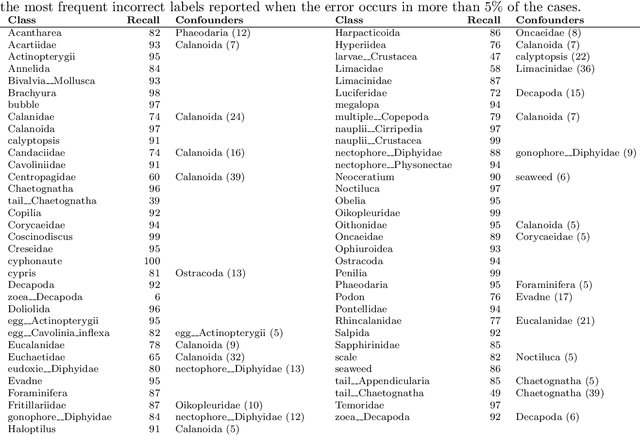
Zooplankton images, like many other real world data types, have intrinsic properties that make the design of effective classification systems difficult. For instance, the number of classes encountered in practical settings is potentially very large, and classes can be ambiguous or overlap. In addition, the choice of taxonomy often differs between researchers and between institutions. Although high accuracy has been achieved in benchmarks using standard classifier architectures, biases caused by an inflexible classification scheme can have profound effects when the output is used in ecosystem assessments and monitoring. Here, we propose using a deep convolutional network to construct a vector embedding of zooplankton images. The system maps (embeds) each image into a high-dimensional Euclidean space so that distances between vectors reflect semantic relationships between images. We show that the embedding can be used to derive classifications with comparable accuracy to a specific classifier, but that it simultaneously reveals important structures in the data. Furthermore, we apply the embedding to new classes previously unseen by the system, and evaluate its classification performance in such cases. Traditional neural network classifiers perform well when the classes are clearly defined a priori and have sufficiently large labeled data sets available. For practical cases in ecology as well as in many other fields this is not the case, and we argue that the vector embedding method presented here is a more appropriate approach.