 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Assumptions to Actions: Turning LLM Reasoning into Uncertainty-Aware Planning for Embodied Agents
Feb 04, 2026Embodied agents operating in multi-agent, partially observable, and decentralized environments must plan and act despite pervasive uncertainty about hidden objects and collaborators' intentions. Recent advances in applying Large Language Models (LLMs) to embodied agents have addressed many long-standing challenges, such as high-level goal decomposition and online adaptation. Yet, uncertainty is still primarily mitigated through frequent inter-agent communication. This incurs substantial token and time costs, and can disrupt established workflows, when human partners are involved. We introduce PCE, a Planner-Composer-Evaluator framework that converts the fragmented assumptions latent in LLM reasoning traces into a structured decision tree. Internal nodes encode environment assumptions and leaves map to actions; each path is then scored by scenario likelihood, goal-directed gain, and execution cost to guide rational action selection without heavy communication. Across two challenging multi-agent benchmarks (C-WAH and TDW-MAT) and three diverse LLM backbones, PCE consistently outperforms communication-centric baselines in success rate and task efficiency while showing comparable token usage. Ablation results indicate that the performance gains obtained by scaling model capacity or reasoning depth persist even when PCE is applied, while PCE consistently raises the baseline across both capacity and reasoning-depth scales, confirming that structured uncertainty handling complements both forms of scaling. A user study further demonstrates that PCE produces communication patterns that human partners perceive as more efficient and trustworthy. Together, these results establish a principled route for turning latent LLM assumptions into reliable strategies for uncertainty-aware planning.
ForceGrip: Data-Free Curriculum Learning for Realistic Grip Force Control in VR Hand Manipulation
Mar 11, 2025



Realistic hand manipulation is a key component of immersive virtual reality (VR), yet existing methods often rely on a kinematic approach or motion-capture datasets that omit crucial physical attributes such as contact forces and finger torques. Consequently, these approaches prioritize tight, one-size-fits-all grips rather than reflecting users' intended force levels. We present ForceGrip, a deep learning agent that synthesizes realistic hand manipulation motions, faithfully reflecting the user's grip force intention. Instead of mimicking predefined motion datasets, ForceGrip uses generated training scenarios-randomizing object shapes, wrist movements, and trigger input flows-to challenge the agent with a broad spectrum of physical interactions. To effectively learn from these complex tasks, we employ a three-phase curriculum learning framework comprising Finger Positioning, Intention Adaptation, and Dynamic Stabilization. This progressive strategy ensures stable hand-object contact, adaptive force control based on user inputs, and robust handling under dynamic conditions. Additionally, a proximity reward function enhances natural finger motions and accelerates training convergence. Quantitative and qualitative evaluations reveal ForceGrip's superior force controllability and plausibility compared to state-of-the-art methods.
LLM-Based Cooperative Agents using Information Relevance and Plan Validation
May 27, 2024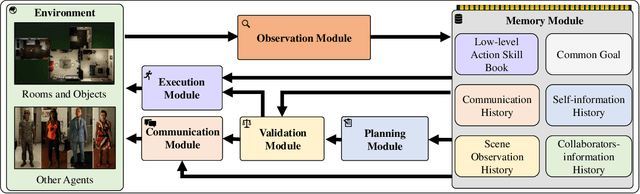
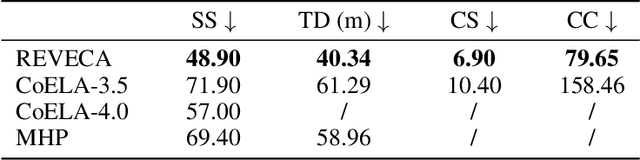
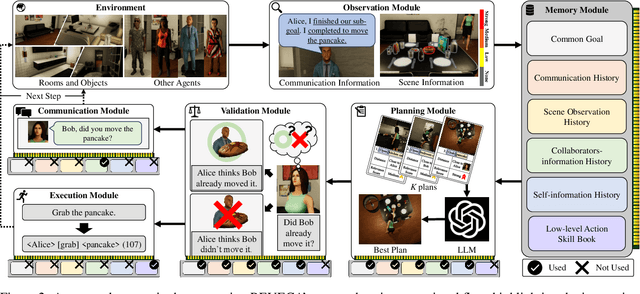

We address the challenge of multi-agent cooperation, where agents achieve a common goal by interacting with a 3D scene and cooperating with decentralized agents under complex partial observations. This involves managing communication costs and optimizing interaction trajectories in dynamic environments. Our research focuses on three primary limitations of existing cooperative agent systems. Firstly, current systems demonstrate inefficiency in managing acquired information through observation, resulting in declining planning performance as the environment becomes more complex with additional objects or goals. Secondly, the neglect of false plans in partially observable settings leads to suboptimal cooperative performance, as agents struggle to adapt to environmental changes influenced by the unseen actions of other agents. Lastly, the failure to incorporate spatial data into decision-making processes restricts the agent's ability to construct optimized trajectories. To overcome these limitations, we propose the RElevance and Validation-Enhanced Cooperative Language Agent (REVECA), a novel cognitive architecture powered by GPT-3.5. REVECA leverages relevance assessment, plan validation, and spatial information to enhance the efficiency and robustness of agent cooperation in dynamic and partially observable environments while minimizing continuous communication costs and effectively managing irrelevant dummy objects. Our extensive experiments demonstrate the superiority of REVECA over previous approaches, including those driven by GPT-4.0. Additionally, a user study highlights REVECA's potential for achieving trustworthy human-AI cooperation. We expect that REVECA will have significant applications in gaming, XR applications, educational tools, and humanoid robots, contributing to substantial economic, commercial, and academic advancements.
3DStyleGLIP: Part-Tailored Text-Guided 3D Neural Stylization
Apr 03, 2024



3D stylization, which entails the application of specific styles to three-dimensional objects, holds significant commercial potential as it enables the creation of diverse 3D objects with distinct moods and styles, tailored to specific demands of different scenes. With recent advancements in text-driven methods and artificial intelligence, the stylization process is increasingly intuitive and automated, thereby diminishing the reliance on manual labor and expertise. However, existing methods have predominantly focused on holistic stylization, thereby leaving the application of styles to individual components of a 3D object unexplored. In response, we introduce 3DStyleGLIP, a novel framework specifically designed for text-driven, part-tailored 3D stylization. Given a 3D mesh and a text prompt, 3DStyleGLIP leverages the vision-language embedding space of the Grounded Language-Image Pre-training (GLIP) model to localize the individual parts of the 3D mesh and modify their colors and local geometries to align them with the desired styles specified in the text prompt. 3DStyleGLIP is effectively trained for 3D stylization tasks through a part-level style loss working in GLIP's embedding space, supplemented by two complementary learning techniques. Extensive experimental validation confirms that our method achieves significant part-wise stylization capabilities, demonstrating promising potential in advancing the field of 3D stylization.